Some codes are sourced from Loony Corn’s Udemy Course (https://www.udemy.com/user/janani-ravi-2/). This post is for personal notes where I summarize the original contents to grasp the key concepts
Graph – Shortest Path Algorithms
Given a graph G with vertices V and edges E
Choose any vertex S – the source
What is the shortest path from S to a specific destination vertex D?
It is the path with the fewest hops to get from S to D
In a weighted graph – visit the neighbour which is connected by an edge with the Lowest Weight
Use a priority queue to implement this
To get the next vertex in the path, pop the element with the Lowest Weight -> It is called Greedy Algorithm
What is a Greedy Algorithm?
Greedy algorithms often fail to find the best solution
A greedy algorithm builds up a solution step by step
A every step it only optimizes for that particular step – It does not look at the overall problem
They do not operate on all the data so they may not see the Big Picture
Greedy algorithms are used for optimization problems
Greedy solutions are especially useful to find approximate solutions to very hard problems which are close to impossible to solve (Technical term NP Hard) E.g, The Traveling Salesman Problem
It’s possible to visit a vertex more than once
We check whether new distance (via the alternative route) is smaller than old distance
new distance = distance[vertex] + weight of edge[vertex, neighbour]
If new distance < original distance [neighbour] then Update the distance table. Put the vertex in Queue (Once Again)
Relaxation
Finding the shortest path in a weighted graph is called Dijkstra’s Algorithm
Shortest Path in Weighted Graph
The algorithm’s efficiency depends on how priority queue is implemented. It’s two operations – Updating the queue and Popping out from the queue determines the running time
Running Time is : O(ELogV) <- If Binary Heaps are used for priority queue
Running time is : O(E + V*V) <- If array is used for priority queue
Sorts the elements of this buffer according to areInIncreasingOrder, using a stable, adaptive merge sort. The adaptive algorithm used is Timsort, modified to perform a straight merge of the elements using a temporary buffer.
Timsort is a hybrid, stablesorting algorithm, derived from merge sort and insertion sort, designed to perform well on many kinds of real-world data. It was implemented by Tim Peters in 2002 for use in the Python programming language. The algorithm finds subsequences of the data that are already ordered (runs) and uses them to sort the remainder more efficiently. This is done by merging runs until certain criteria are fulfilled. Timsort was Python’s standard sorting algorithm from version 2.3 to version 3.10,[5] and is used to sort arrays of non-primitive type in Java SE 7,[6] on the Android platform,[7] in GNU Octave,[8] on V8,[9]Swift,[10] and inspired the sorting algorithm used in Rust.[11]
It uses techniques from Peter McIlroy’s 1993 paper “Optimistic Sorting and Information Theoretic Complexity”.
public class Node {
public var prev: Node?
public var next: Node?
public var id: String
public var data: String
public init(prev: Node? = nil, next: Node? = nil, id: String, data: String) {
self.prev = prev
self.next = next
self.id = id
self.data = data
}
}
public class LRUCacheDoublyLinkedList {
private var size: Int = 0
let capacity: Int
private var head: Node?
private var tail: Node?
private var dict: [String: Node] = [:]
public init(capacity: Int) {
self.capacity = capacity
}
//Update the node to be the head
private func update(_ node: Node) {
let prev = node.prev
let next = node.next
//It is a middle node in the list
if prev != nil {
prev?.next = next
}
else {
//This case It is first node(head)
head = next
}
//If it is not last node
if next != nil {
next?.prev = prev
}
else {
//It is the last node (tail)
tail = prev
}
add(node)
}
//get item with ID and move to the head because It used
public func get(_ id: String) -> Node? {
guard let node = dict[id] else {
return nil
}
update(node)
return node
}
//Always add node at Head
private func add(_ node: Node) {
node.next = head
if head != nil {
head?.prev = node
}
//Set new head node
head = node
//If there is 1 node in the list, it is the head as well as the tail
if tail == nil {
tail = node
}
dict[node.id] = node
}
private func removeTail() {
let tailId = tail?.id
var cachedTail: Node?
if let tailId = tail?.id, let lastNode = dict[tailId] {
cachedTail = lastNode
}
tail = tail?.prev
if tail != nil {
tail?.next = nil
}
if let tailId {
dict.removeValue(forKey: tailId)
}
cachedTail = nil
}
public func put(id: String, data: String) {
if let node = dict[id] {
node.data = data
update(node)
return
}
//the data is not present in the cache so insert
let newNode = Node(id: id, data: data)
//Check cache size
if size < capacity {
size += 1
//insert into the cache and set it to be the head node
add(newNode)
}
else {
//cache is full, remove the last item and insert new one
removeTail()
add(newNode)
}
}
public func printAll() {
var pointNode = head
while pointNode != nil {
if let data = pointNode?.data {
print("\(data)", terminator: pointNode?.next != nil ? " -> " : "")
}
pointNode = pointNode?.next
}
print("\n")
}
}
Some codes are sourced from Loony Corn’s Udemy Course (https://www.udemy.com/user/janani-ravi-2/). This post is for personal notes where I summarize the original contents to grasp the key concepts
General Programming Problems
Often coding interviews involve problems which do not have complicated algorithms or data structures – These are straight programming problems
They test your ability to work through details and get the edge cases right
The bad thing about them is that they involve lots of cases which you need to work through – They tend to be frustrating
The great thing about them is that if you are organised and systematic in your thought process it is reasonably straightforward to get them right
These are problems you should nail. All they need is practice
None of them require any detailed knowledge of standard algorithms
We’ll solve 8 general programming problems here – They all use arrays or simple data structures which you create
Example 1. Check whether a given string is a palindrome
Palindromes are strings which read the same when read forwards or backwards
You can reverse all the letters in a palindrome and get the original string
Examples of palindromes are
MADAM, REFER, LONELY TYLENOL
Note
the string can have spaces, ignore spaces in the palindrome check, the spaces can all be collapsed
The check is Case-Insenstive
public func isPalindrome(_ input: String) -> Bool {
var firstIndex = 0
var lastIndex = input.count - 1
let lowerCasedInput = Array(input.lowercased())
print(lowerCasedInput)
while firstIndex < lastIndex {
var first: Character? = lowerCasedInput[firstIndex]
var last: Character? = lowerCasedInput[lastIndex]
while lowerCasedInput[firstIndex] == " " {
firstIndex += 1
first = lowerCasedInput[firstIndex]
}
while lowerCasedInput[lastIndex] == " " {
lastIndex -= 1
last = lowerCasedInput[lastIndex]
}
print("First char: \(first) Last char: \(last)")
if first != last {
return false
}
firstIndex += 1
lastIndex -= 1
print("First index: \(firstIndex)")
print("Last index: \(lastIndex)")
}
return true
}
isPalindrome("MaIay a Ia m") //True
isPalindrome("MADAM") //True
isPalindrome("REFER") //True
isPalindrome("LONELY TYLENOL") //True
isPalindrome("LONELY TYLENOLF") //False
Example 2. Find all points within a certain distance of another point
Find points (Given X, Y coordinates) which are within a certain distance of another point. The distance and the central point is specified as an argument to the function which computes the points in range
Example. All points within a distance 10 of (0,0) will include the point at (3, 4) but not include the point at (12, 13)
Hint: If you are using an OO Programming language set up an entity which represents a point and contains methods within it to find the distance from another point.
public struct Point {
public let x: Double
public let y: Double
public init(x: Double, y: Double) {
self.x = x
self.y = y
}
}
extension Point {
public func getDistance(_ otherPoint: Point) -> Double {
//Distance: sqrt(x^2 + y^2)
return sqrt(pow(otherPoint.x - x, 2) + pow(otherPoint.y - y, 2))
}
public func isWithinDistance(_ otherPoint: Point, distance: Double) -> Bool {
let distanceX = abs(x - otherPoint.x)
let distanceY = abs(y - otherPoint.y)
if distanceX > distance || distanceY > distance {
return false
}
return getDistance(otherPoint) <= distance
}
}
public func getPointsWithinDistance(points: [Point], center: Point, distance: Double) -> [Point] {
var withinPoints = [Point]()
for point in points {
if point.isWithinDistance(center, distance: distance) {
withinPoints.append(point)
}
}
print("Points within \(distance) of point x: \(center.x) y: \(center.y)")
for p in withinPoints {
print("Point: x: \(p.x) y: \(p.y)")
}
return withinPoints
}
Example 3. Game of Life: Get the next generation of cell states
A cell is a block in a matrix surrounded by neighbours. A cell can be in two states, alive or dead. A cell can change its state from one generation to another under certain circumstances
Rule
A live cell with fewer than 2 live neighbours dies of loneliness
A dead cell with exactly 2 live neighbours comes alive
A live cell with greater than 2 live neighbours dies due to overcrowding
Given a current generation of cells in a matrix, what does the next generation look like? Which cells are alive and which are dead? Write code to get the next generation of cells given the current generation
Hint
Represent each generation as rows and columns in a 2D matrix. Live and Dead states can be represented by integers or boolean states
func printMatrix(_ input: [[Int]]) {
for row in 0..<input.count {
print("|", terminator: "")
for col in 0..<input[0].count {
print("\(input[row][col])", terminator: "|")
}
print("\n")
}
}
public func getNextGeneration(currentGeneration: [[Int]]) -> [[Int]] {
var nextGeneration = currentGeneration
let rowCount = currentGeneration.count
let colCount = currentGeneration[0].count
for row in 0..<rowCount {
for col in 0..<colCount {
let nextState = getNextState(
currentGeneration: currentGeneration,
row: row,
col: col
)!
nextGeneration[row][col] = nextState
}
}
return nextGeneration
}
//0: Dead, 1: Alive
public func getNextState(currentGeneration: [[Int]], row: Int, col: Int) -> Int? {
//Edge case
if currentGeneration.isEmpty {
return nil
}
if row > currentGeneration.count {
return nil
}
if col > currentGeneration[0].count {
return nil
}
var states = [Int: Int]()
let currentState = currentGeneration[row][col]
let rowCount = currentGeneration.count
let colCount = currentGeneration[0].count
//Check 8 directions
if col - 1 >= 0 {
if let value = states[currentGeneration[row][col - 1]]{
states[currentGeneration[row][col - 1]] = value + 1
}
else {
states[currentGeneration[row][col - 1]] = 1
}
}
if col - 1 >= 0, row - 1 >= 0 {
if let value = states[currentGeneration[row - 1][col - 1]]{
states[currentGeneration[row - 1][col - 1]] = value + 1
}
else {
states[currentGeneration[row - 1][col - 1]] = 1
}
}
if col - 1 >= 0, row + 1 < rowCount {
if let value = states[currentGeneration[row + 1][col - 1]]{
states[currentGeneration[row + 1][col - 1]] = value + 1
}
else {
states[currentGeneration[row + 1][col - 1]] = 1
}
}
if col + 1 < colCount {
if let value = states[currentGeneration[row][col + 1]]{
states[currentGeneration[row][col + 1]] = value + 1
}
else {
states[currentGeneration[row][col + 1]] = 1
}
}
if col + 1 < colCount, row - 1 >= 0 {
if let value = states[currentGeneration[row - 1][col + 1]]{
states[currentGeneration[row - 1][col + 1]] = value + 1
}
else {
states[currentGeneration[row - 1][col + 1]] = 1
}
}
if col + 1 < colCount, row + 1 < rowCount {
if let value = states[currentGeneration[row + 1][col + 1]]{
states[currentGeneration[row + 1][col + 1]] = value + 1
}
else {
states[currentGeneration[row + 1][col + 1]] = 1
}
}
if row + 1 < rowCount {
if let value = states[currentGeneration[row + 1][col]]{
states[currentGeneration[row + 1][col]] = value + 1
}
else {
states[currentGeneration[row + 1][col]] = 1
}
}
if row - 1 >= 0 {
if let value = states[currentGeneration[row - 1][col]]{
states[currentGeneration[row - 1][col]] = value + 1
}
else {
states[currentGeneration[row - 1][col]] = 1
}
}
if currentState == 0 {
//A dead cell with exactly 2 live neighbours comes alive
let livedCount = states[1] ?? 0
return livedCount == 2 ? 1 : 0
}
else {
let livedCount = states[1] ?? 0
//A live cell with fewer than 2 live neighbours dies of loneliness
//A live cell with greater than 2 live neighbours dies due to overcrowding
if livedCount < 2 || livedCount >= 2 {
return 0
}
return currentState
}
}
Example 4. Break A document into chunks
A document is stored in the cloud and you need to send the text of the document to the client which renders it on the screen (Think Google docs)
You do not want to send the entire document to the client at one go, you want to send it chunk by chunk. A chunk can be created subject to certain constraints
Rule
A chunk can be 5000 or fewer characters in length (This rule is relaxed only under one condition see below)
A chunk should contain only complete paragraphs – This is a hard and fast rule
A paragraph is represented by the ‘:’ Character in the document
List of chunks should be in the order in which they appear in the document (Do not set them up out of order)
If you encounter a paragraph > 5000 characters that should be in a separate chunk by itself
Get all chunks as close to 5000 characters as possible, subject to the constraints above
Given a string document return a list of chunks which some other system can use to send to the client
Hint: public func chunkify(doc: String) -> [String]
public func chunkify(doc: String, chunkSize: Int) -> [String] {
guard !doc.isEmpty else {
return []
}
var chunks = [String]()
let paragraphs = doc.split(separator: ":")
var start = 0
let total = paragraphs.count
while start < total {
var chunk = paragraphs[start] + ":"
if chunk.count <= chunkSize {
var next = start + 1
while next < total, paragraphs[next].count + 1 <= chunkSize - chunk.count {
chunk += (paragraphs[next] + ":")
next += 1
}
chunks.append(String(chunk))
start = next
}
else {
chunks.append(String(chunk))
start += 1
}
}
return chunks
}
Example 5. Run Length Encoding and Decoding
Write code which encodes a string using Run-Length encoding and decodes a string encoded using Run-Length encoding
Example
ABBCCC -> 1A2B3C
AABBBCCCC -> 2A3B4C
1D2E1F -> DEEF
Constraints
Assume only letters are present in the string to be encode, no numbers
Remember to handle the case where we can have > 9 of the same characters in a row
Run-Length Encoding Code
public func runLengthEncoding(_ input: String) -> String {
var result = ""
var start = 0
let arrayInput = Array(input)
while start < arrayInput.count {
var count = 1
let currentCharacter = arrayInput[start]
var next = start + 1
while next < arrayInput.count, arrayInput[next] == currentCharacter {
count += 1
next += 1
}
result += "\(count)\(currentCharacter)"
start = next
}
return result
}
Run-Length Decoding Code
public func runLengthDecoding(_ input: String) -> String {
var result = ""
var start = 0
let arrayInput = Array(input)
//Assumed that first character start with number
while start < arrayInput.count {
//Step 1. Get number
var numberStr = String(arrayInput[start])
//Edge case. Larger than 9
var next = start + 1
while next < arrayInput.count, Int(String(arrayInput[next])) != nil {
numberStr += String(arrayInput[next])
print(numberStr)
next += 1
}
let repeatedCount = Int(numberStr) ?? 1
//Step 2. Generate repeated characters
result += String(repeating: arrayInput[next], count: repeatedCount)
//Step 3. Important! Pointing to next number
start = next + 1
}
return result
}
Example 6. Add two numbers represented by their digits
Given two numbers where the individual digits in the numbers are in an array or a list add them to get the final result in the same list or array form
Example using Arrays: [1, 2] represents the number 12. Note that the most significant digit in the 0th index of the array, with the least significant digit at the last position
Adding [1, 2] and [2, 3] should give the result [3, 5]
Requirements
Don’t convert the number format to a real number to add them. Add them digit by digit
Remember to consider the carry over per digit if there is one!
public func add(a: [Int], b: [Int]) -> [Int] {
var result = [Int]()
let maxLength = max(a.count, b.count)
var carry = 0
var currentIndexA = a.count == maxLength ? maxLength - 1 : a.count - 1
var currentIndexB = b.count == maxLength ? maxLength - 1 : b.count - 1
while currentIndexA >= 0, currentIndexB >= 0 {
var sum = a[currentIndexA] + b[currentIndexB] + carry
if sum > 9 {
carry = sum / 10
sum = sum % 10
}
else {
carry = 0
}
result.insert(sum, at: 0)
currentIndexA -= 1
currentIndexB -= 1
}
if currentIndexA >= 0 {
while currentIndexA >= 0 {
var sum = a[currentIndexA] + carry
if sum > 9 {
carry = sum / 10
sum = sum % 10
}
else {
carry = 0
}
result.insert(sum, at: 0)
currentIndexA -= 1
}
}
if currentIndexB >= 0 {
while currentIndexB >= 0 {
var sum = a[currentIndexB] + carry
if sum > 9 {
carry = sum / 10
sum = sum % 10
}
else {
carry = 0
}
result.insert(sum, at: 0)
currentIndexB -= 1
}
}
if carry != 0 {
result.insert(carry, at: 0)
}
return result
}
Example 7. Increment number by 1
Suppose that you invent your own numeral system (which is neither decimal, binary nor any of the common ones). You specify the digits and the order of the digits in that numeral system.
Given the digits and the order of digits used in that system and a number, write a function to increment that number by 1 and return the result
Solution 1
public func incrementByOne(input: String) -> String? {
var result = [String]()
let numeralSystem = ["A": 0, "B": 1, "C": 2, "D": 3]
var input = Array(input).compactMap { "\($0)"}
var validCount = 0
for char in input {
if numeralSystem.keys.contains(char) {
validCount += 1
}
}
if validCount != input.count {
return nil
}
var currentIndex = input.count - 1
var carry = 0
while currentIndex >= 0 {
var sum = numeralSystem[input[currentIndex]]! + carry
if currentIndex == input.count - 1 {
sum += 1
}
if sum > 3 {
carry = sum / 4
sum = sum % 4
}
else {
carry = 0
}
if let key = numeralSystem.first (where: { $0.value == sum })?.key {
result.insert(key, at: 0)
}
currentIndex -= 1
}
if carry != 0 {
if let key = numeralSystem.first (where: { $0.value == carry })?.key {
result.insert(key, at: 0)
}
}
return result.joined()
}
Solution 2
public func incrementByOne2(input: String) -> String? {
let numeralSystem = ["A", "B", "C", "D"]
var input = Array(input).compactMap { "\($0)" }
var validCount = 0
for char in input {
if numeralSystem.contains(char) {
validCount += 1
}
}
if validCount != input.count {
return nil
}
var currentIndex = input.count - 1
var isCompleted = false
while !isCompleted, currentIndex >= 0 {
let currentDigit = input[currentIndex]
let indexOfCurrentDigit = numeralSystem.firstIndex(of: currentDigit)
//Get the next digit on increment, this will wrap around to the first digit which is why we use the modulo operator
let indexOfNextDigit = (indexOfCurrentDigit! + 1) % numeralSystem.count
//Update digit
input[currentIndex] = numeralSystem[indexOfNextDigit]
if indexOfNextDigit != 0 {
isCompleted = true
}
//If we're at the most significant digit and that wrapped around we add a new digit to the incremented number like going from 9 to 10
if currentIndex == 0, indexOfNextDigit == 0 {
input.insert(numeralSystem[0], at: 0)
}
currentIndex -= 1
}
return input.joined()
}
Example 8. Sudoku
Basic rules
Each rows and columnsshould have one value (1-9) -> Should not have duplicated value
Board size is 9×9
Block size is 3×3, Total 9 blocks
In a Block, Should have one value (1-9) -> Should not have duplicated value
Exercise 1. isValidRowsAndCols
This function is returns boolean. If all the row and column’s values are valid then It returns true. otherwise returns false.
var sudoku: [[Int]] = [
[8, 0, 0, 4, 0, 6, 0, 0, 7],
[0, 0, 0, 0, 0, 0, 4, 0, 0],
[0, 1, 0, 0, 0, 0, 6, 5, 0],
[5, 0, 9, 0, 3, 0, 7, 8, 0],
[0, 0, 0, 0, 7, 0, 0, 0, 0],
[0, 4, 8, 0, 2, 0, 1, 0, 3],
[0, 5, 2, 0, 0, 0, 0, 0, 0],
[0, 0, 1, 0, 0, 0, 0, 0, 0],
[3, 0, 0, 9, 0, 2, 0, 0, 5]
]
//Helper
func printBoard(_ input: [[Int]]) {
for row in 0..<9 {
print("|", terminator: "")
for col in 0..<9 {
print("\(input[row][col])", terminator: "|")
}
print("\n")
}
}
func isValidRowsAndCols(_ board: [[Int]]) -> Bool {
var rowSet: [Int: Set<Int>] = [:]
var colSet: [Int: Set<Int>] = [:]
//Index starts from 0 to 8
for i in 0...8 {
rowSet[i] = Set()
colSet[i] = Set()
}
for row in 0...8 {
for col in 0...8 {
var cellValue = board[row][col]
//No value has assigned
if cellValue == 0 {
continue
}
if cellValue < 0 || cellValue > 9 {
return false
}
//cellValue already seen
if rowSet[row]?.contains(cellValue) == true {
print("💥 Invalid: \(row):\(col) -> value: \(cellValue)")
return false
}
if colSet[col]?.contains(cellValue) == true {
print("💥 Invalid: \(row):\(col) -> value: \(cellValue)")
return false
}
//Add current cell value to the row or column set
rowSet[row]?.insert(cellValue)
colSet[col]?.insert(cellValue)
}
}
return true
}
isValidRowsAndCols(sudoku) //It returns true
Exercise 2. IsValidBlock -> Bool
Each block should have values between 1-9. And each cell should not have a duplicate value in a block.
func isValidBlock(_ board: [[Int]]) -> Bool {
//Set associated with every block
var blockSet: [Int: Set<Int>] = [:]
for i in 0..<9 {
blockSet[i] = Set()
}
//Row block is 3
for rowBlock in 0...2 {
for colBlock in 0...2 {
//Check 3x3 Block Cell
for miniRow in 0...2 {
for miniCol in 0...2 {
let row = rowBlock * 3 + miniRow
let col = colBlock * 3 + miniCol
let cellValue = sudoku[row][col]
if cellValue == 0 {
continue
}
if cellValue < 0 || cellValue > 9 {
return false
}
/* Total 9 block
row0: 0 1 2
row1: 3 4 5
row2: 6 7 8
*/
let blockNumber = rowBlock * 3 + colBlock
if blockSet[blockNumber]?.contains(cellValue) == true {
return false
}
blockSet[blockNumber]?.insert(cellValue)
}
}
}
}
return true
}
isValidBlock(sudoku) // It returns true
Exercise 3. isValidSudoku -> Bool
This function checks all the cells in board and checks the sudoku rule.
As you can see when you select a cell (yellow), You need to check blue areas.
Step 1. Create a Sudoku Board
Generate Sudoku Board
func generateSudoku(board: inout [[Int]]) {
//Has a 9 mini blocks. diagonal direction
//3 means jumping to next mini block, It loops 3 blocks and fill the numbers
for i in stride(from: 0, through: 8, by: 3) {
var numbers = [1, 2, 3, 4, 5, 6, 7, 8, 9].shuffled()
for miniRow in 0...2 {
for miniCol in 0...2 {
board[miniRow][miniCol] = numbers.removeFirst()
}
}
}
//Step 2. solve function to fill the all numbers
_ = solve(board: &board)
var numberOfEmptyCell = 50
while numberOfEmptyCell > 0 {
var random = [0, 1, 2, 3, 4, 5, 6, 7, 8].shuffled()
board[random.first!][random.last!] = 0
numberOfEmptyCell -= 1
}
//TODO: Step 3. set empty cells It depends on difficulty
}
Helper functions
import Foundation
//https://github.com/ShawnBaek/Table
import Table
//Check If Sudoku board has empty cell or not
func isFilledAllNumbers(board: [[Int]]) -> Bool {
var numberOfEmptyCell = 0
for row in 0...8 {
for col in 0...8 {
if board[row][col] == 0 {
numberOfEmptyCell += 1
}
}
}
return numberOfEmptyCell == 0
}
//Get emptyCell's position
func emptyCell(board: [[Int]]) -> (row: Int, col: Int)? {
for row in 0...8 {
for col in 0...8 {
//Empty cell found
if board[row][col] == 0 {
return (row: row, col: col)
}
}
}
return nil
}
func canPlace(_ number: Int, row: Int, col: Int, board: [[Int]]) -> Bool {
//Sudoku rule
//Rule 1. Check unique number in a row
for r in 0...8 {
if board[r][col] == number {
return false
}
}
//Rule 2. Check unique number in a col
for c in 0...8 {
if board[row][c] == number {
return false
}
}
//Rule 3. Check unique number in a mini block -> total 9
//each block's start position will be 0,0 3,3, 6,6, and so on
//If row is between 3-5, 3...5 / 3 = 1, 1 * 3 = 3
let miniBlockStartRow = (row / 3) * 3
let miniBlockStartCol = (col / 3) * 3
for miniRow in 0...2 {
for miniCol in 0...2 {
let boardRow = miniBlockStartRow + miniRow
let boardCol = miniBlockStartCol + miniCol
if board[boardRow][boardCol] == number {
return false
}
}
}
return true
}
Sudoku Board solve function
Step 1. Check isFilledAllNumber or not.
It assumed that generated board is a valid sudoku board. All we need to do is fill the correct number on empty cell
Step 2. Recursively calling a function – Get empty cell and fill the correct number
//It is a recursive function
func solve(board: inout [[Int]]) -> Bool {
//Base case
//If this board filled all numbers? -> yes then return true
//func isFilledAllNumbers -> Bool
//Game done
if isFilledAllNumbers(board: board) {
return true
}
//Step 1. Get the emptyCell and finding a number to place
//one more function to get emptyCell
if let emptyCellPosition = emptyCell(board: board) {
//Can place 1-9 numbers
for number in 1...9 {
//Check can place a number at this position
if canPlace(number, row: emptyCellPosition.row, col: emptyCellPosition.col, board: board) {
//Place a number
board[emptyCellPosition.row][emptyCellPosition.col] = number
//Recursive Case
if solve(board: &board) {
return true
}
//Reset to emptyCell
board[emptyCellPosition.row][emptyCellPosition.col] = 0
}
}
}
return false
}
Check Validation
func isValidRowsAndCols(_ board: [[Int]]) -> Bool {
var rowSet: [Int: Set<Int>] = [:]
var colSet: [Int: Set<Int>] = [:]
//Index starts from 0 to 8
for i in 0...8 {
rowSet[i] = Set()
colSet[i] = Set()
}
for row in 0...8 {
for col in 0...8 {
let cellValue = board[row][col]
//No value has assigned
if cellValue == 0 {
continue
}
if cellValue < 0 || cellValue > 9 {
return false
}
//cellValue already seen
if rowSet[row]?.contains(cellValue) == true {
return false
}
if colSet[col]?.contains(cellValue) == true {
return false
}
//Add current cell value to the row or column set
rowSet[row]?.insert(cellValue)
colSet[col]?.insert(cellValue)
}
}
return true
}
func isValidBlock(_ board: [[Int]]) -> Bool {
//Set associated with every block
var blockSet: [Int: Set<Int>] = [:]
for i in 0..<9 {
blockSet[i] = Set()
}
var test = 0
//Row block is 3
for rowBlock in 0...2 {
for colBlock in 0...2 {
print("Start Block: \(test)")
//Check 3x3 Block Cell
for miniRow in 0...2 {
for miniCol in 0...2 {
let row = rowBlock * 3 + miniRow
let col = colBlock * 3 + miniCol
let cellValue = board[row][col]
if cellValue == 0 {
continue
}
if cellValue < 0 || cellValue > 9 {
return false
}
/* Total 9 block
row0: 0 1 2
row1: 3 4 5
row2: 6 7 8
*/
let blockNumber = rowBlock * 3 + colBlock
if blockSet[blockNumber]?.contains(cellValue) == true {
return false
}
blockSet[blockNumber]?.insert(cellValue)
}
}
test += 1
}
}
return true
}
func isValid(_ board: [[Int]]) -> Bool {
if !isValidRowsAndCols(board) {
return false
}
if !isValidBlock(board) {
return false
}
return true
}
Some codes and contents are sourced from Apple, WWDC and BigMountStudio. This post is for personal notes where I summarize the original contents to grasp the key concepts(🎨 some images I draw it)
Overview
The Combine framework provides a declarative approach for how your app processes events. Rather than potentially implementing multiple delegate callbacks or completion handler closures, you can create a single processing chain for a given event source. Each part of the chain is a Combine operator that performs a distinct action on the elements received from the previous step.
I used delay, between publisher and subscriber. It controlling the timing like debounce and throttle. Above the example, It prints 1, 2, 3, 4 after 3 seconds.
Subscriber
It has two main feature.
receive
assign
Operators
It adopts publisher and send results to subscriber
Upstream: Publisher – Subscribes to Publisher
Downstream: Subscriber – Sends results to a Subscriber
Publisher’s map function. It’s upstream is self
Subjects
A publisher that exposes a method for outside callers to publish elements.
A subject is a publisher that you can use to ”inject” values into a stream, by calling its send(_:) method. This can be useful for adapting existing imperative code to the Combine model.
CurrentValueSubject
PassthroughSubject
PassthroughSubject
A subject that broadcasts elements to downstream subscribers.
Unlike CurrentValueSubject, a PassthroughSubject doesn’t have an initial value or a buffer of the most recently-published element. A PassthroughSubject drops values if there are no subscribers, or its current demand is zero.
CurrentValueSubject
A subject that wraps a single value and publishes a new element whenever the value changes.
A publisher that transforms elements from an upstream publisher into a publisher of that element’s type.
Combine‘s flatMap(maxPublishers:_:) operator performs a similar function to the flatMap(_:) operator in the Swift standard library, but turns the elements from one kind of publisher into a new publisher that is sent to subscribers. Use flatMap(maxPublishers:_:) when you want to create a new series of events for downstream subscribers based on the received value. The closure creates the new Publisherbased on the received value. The new Publisher can emit more than one event, and successful completion of the new Publisher does not complete the overall stream. Failure of the new Publisher causes the overall stream to fail.
In the example below, a PassthroughSubject publishes WeatherStation elements. The flatMap(maxPublishers:_:) receives each element, creates a URL from it, and produces a new URLSession.DataTaskPublisher, which will publish the data loaded from that URL.
public struct WeatherStation {
public let stationID: String
}
var weatherPublisher = PassthroughSubject<WeatherStation, URLError>()
cancellable = weatherPublisher.flatMap { station -> URLSession.DataTaskPublisher in
let url = URL(string:"https://weatherapi.example.com/stations/\(station.stationID)/observations/latest")!
return URLSession.shared.dataTaskPublisher(for: url)
}
.sink(
receiveCompletion: { completion in
// Handle publisher completion (normal or error).
},
receiveValue: {
// Process the received data.
}
)
weatherPublisher.send(WeatherStation(stationID: "KSFO")) // San Francisco, CA
weatherPublisher.send(WeatherStation(stationID: "EGLC")) // London, UK
weatherPublisher.send(WeatherStation(stationID: "ZBBB")) // Beijing, CN
Future – Publisher
A publisher that eventually produces a single value and then finishes or fails.
Use a future to perform some work and then asynchronously publish a single element. You initialize the future with a closure that takes a Future.Promise; the closure calls the promise with a Result that indicates either success or failure. In the success case, the future’s downstream subscriber receives the element prior to the publishing stream finishing normally. If the result is an error, publishing terminates with that error.
Above the example, when you call a function It create a Future publisher. As you can see Future has finished after send a value (200)
Apple’s example
func generateAsyncRandomNumberFromFuture() -> Future <Int, Never> {
return Future() { promise in
DispatchQueue.main.asyncAfter(deadline: .now() + 2) {
let number = Int.random(in: 1...10)
promise(Result.success(number))
}
}
}
cancellable = generateAsyncRandomNumberFromFuture()
.sink { number in print("Got random number \(number).") }
//async-await syntax
let number = await generateAsyncRandomNumberFromFuture().value
print("Got random number \(number).")
//Alternative to Futures
func generateAsyncRandomNumberFromContinuation() async -> Int {
return await withCheckedContinuation { continuation in
DispatchQueue.main.asyncAfter(deadline: .now() + 2) {
let number = Int.random(in: 1...10)
continuation.resume(returning: number)
}
}
}
let asyncRandom = await generateAsyncRandomNumberFromContinuation()
Demand – Publisher
A publisher that awaits subscription before running the supplied closure to create a publisher for the new subscriber.
Unlike Future Publisher, It deferred publisher will not execute immediately when It is created. It will execute every time a subscriber is attached.
You can use it for many of Apple’s Kits where you need to get information from a device, or ask the user for permissions to access something, like photos, or other private or sensitive information
The following example uses a sequence publisher as a counter to publish three random numbers, generated by a map(_:) operator. It uses a share() operator to share the same random number to each of two subscribers. This example uses a delay(for:tolerance:scheduler:options:) operator only to prevent the first subscriber from exhausting the sequence publisher immediately; an asynchronous publisher wouldn’t need this.
Without the share() operator, stream 1 receives three random values, followed by stream 2 receiving three different random values.
Also note that Publishers.Share is a class rather than a structure like most other publishers. This means you can use this operator to create a publisher instance that uses reference semantics.
Example 1. Without Share – received values are different
Example 2. With share() – received values are the same
Connect / AutoConnect – Use for ConnectablePublisher
Sometimes, you want to configure a publisher before it starts producing elements, such as when a publisher has properties that affect its behavior. But commonly used subscribers like sink(receiveValue:) demand unlimited elements immediately, which might prevent you from setting up the publisher the way you like. A publisher that produces values before you’re ready for them can also be a problem when the publisher has two or more subscribers. This multi-subscriber scenario creates a race condition: the publisher can send elements to the first subscriber before the second even exists.
Consider the scenario in the following figure. You create a URLSession.DataTaskPublisher and attach a sink subscriber to it (Subscriber 1) which causes the data task to start fetching the URL’s data. At some later point, you attach a second subscriber (Subscriber 2). If the data task completes its download before the second subscriber attaches, the second subscriber misses the data and only sees the completion.
To prevent a publisher from sending elements before you’re ready, Combine provides the ConnectablePublisher protocol. A connectable publisher produces no elements until you call its connect() method. Even if it’s ready to produce elements and has unsatisfied demand, a connectable publisher doesn’t deliver any elements to subscribers until you explicitly call connect().
The following figure shows the URLSession.DataTaskPublisher scenario from above, but with a ConnectablePublisher ahead of the subscribers. By waiting to call connect() until both subscribers attach, the data task doesn’t start downloading until then. This eliminates the race condition and guarantees both subscribers can receive the data.
To use a ConnectablePublisher in your own Combine code, use the makeConnectable() operator to wrap an existing publisher with a Publishers.MakeConnectable instance. The following code shows how makeConnectable() fixes the data task publisher race condition described above. Typically, attaching a sink — identified here by the AnyCancellable it returns, cancellable1 — would cause the data task to start immediately. In this scenario, the second sink, identified as cancellable2, doesn’t attach until one second later, and the data task publisher might complete before the second sink attaches. Instead, explicitly using a ConnectablePublisher causes the data task to start only after the app calls connect(), which it does after a two-second delay.
Some Combine publishers already implement ConnectablePublisher, such as Publishers.Multicast and Timer.TimerPublisher. Using these publishers can cause the opposite problem: having to explicitly connect() could be burdensome if you don’t need to configure the publisher or attach multiple subscribers.
The following example uses autoconnect(), so a subscriber immediately receives elements from a once-a-second Timer.TimerPublisher. Without autoconnect(), the example would need to explicitly start the timer publisher by calling connect() at some point.
let cancellable = Timer.publish(every: 1, on: .main, in: .default)
.autoconnect()
.sink() { date in
print ("Date now: \(date)")
}
Some codes and contents are sourced from Udemy. This post is for personal notes where I summarize the original contents to grasp the key concepts(🎨 some images I draw it)
Graph
A graph is used to represent relationships between entities
Graphs are used to represent information in many many real world applications
Graphs are also favorite interview questions – They can start from simple concepts and get arbitrarily complex
Graph theory is a complex field of study by itself – There are many algorithms to optimize different problems represented using graphs
First principle of graph can solve most of the graph problems
Vertex
The entities can be anything – Graphs find applications in variety of ways in the real word
Edge
These relationships can be arbitrarily complicated and of a variety of different types
Real wordExample
LinkedIn (Professional Graph)
Entities: People
Edge: Professional relationships – people work together
Facebook (Social Graph)
Entities: People
Edge: Personal relationships – People are friends
GoogleMaps (Locations)
Entities: Locations
Edge: A way to get from one location to another – Roads, Rail, Air
Each of these can be further thought of in terms of specific means of transport
Bus, Car, Taxi, Individual trains, Airlines
at&t (Phone network)
Entities: Old fashioned phones – landlines
Edge: A network to carry voice from one instrument to another
cisco / google and more (Internet)
Entities: Computers across the world
Edge: A way to send information or data from one computer to another
This can information can be routed wirelessly or over wires
enum GraphType {
case directed
case undirected
}
protocol Graph {
func addEdge(src: Int, dst: Int)
//Helper to get the adjacent vertices for any vertex - A method which is required for all algorithms involving graphs
func getAdjacentVertices(vertext: Int) -> [Int]?
}
Adjacency Matrix
Use A Matrix with Rows and Columns – It just a Table
The row labels and the column labels represent the vertices
Each cell represents the relationship between the vertices. I.E. The edges
enum GraphType {
case directed
case undirected
}
protocol Graph {
func addEdge(src: Int, dst: Int)
func getAdjacentVertices(vertext: Int) -> [Int]?
}
class AdjacencyMatrix: Graph {
private var matrix: [[Int]]
private let type: GraphType
init(vertices: [Int], graphType: GraphType) {
matrix = Array(
repeating: Array(
repeating: 0,
count: vertices.count
), count: vertices.count
)
type = graphType
}
func addEdge(src: Int, dst: Int) {
let range = 0..<matrix[0].count
guard range ~= src, range ~= dst else {
return
}
matrix[src][dst] = 1
if type == .undirected {
matrix[dst][src] = 1
}
}
func getAdjacentVertices(vertext: Int) -> [Int]? {
let range = 0..<matrix[0].count
guard range ~= vertext else {
return nil
}
var result = [Int]()
for i in 0..<matrix[0].count {
//If 1 is present in the cell it means that the vertext V is directly connected to another vertex
if matrix[vertext][i] == 1 {
result.append(i)
}
}
//Always return the vertices in ascending order - to compare with other values's adjacents
return result.sorted(by: { $0 < $1 })
}
}
Adjacency List
Each vertex is a node
Each vertex has a pointer to a linked list
This linked list contains all the other nodes this vertex connects to directly
If a vertex V has an edge leading to another vertex U
🔥 BFS is not using a recursive call. Don’t put below logicinside bfsGraph function!
//This for loop ensures that all nodes are covered even for an unconnected graph
for i in 0..<visited.count {
bfsGraph(graph: graph, visited: &visited, currentVertext: i)
}
Exercise 1. Topological Sort
It is an ordering of vertices in a directed acyclic graph in which each node comes before all the nodes to which
If there are vertices which has no incoming edge, you can start any of vertex among them.
Indegree
Number of inward directed graph edges for a given graph vertex
Indegree of vertex 0 is 0
If there were no vertices with 0 indegree, then there would have been no topological sort -> The graph has a cycle.
It is an ordering of vertices in a Directed Acyclic Graph in which each node comes before all the nodes to which. It has outgoing edges
Final code for topological sort. (I added 2 functions)
enum GraphType {
case directed
case undirected
}
protocol Graph {
func addEdge(src: Int, dst: Int)
func getAdjacentVertices(vertext: Int) -> [Int]?
//New functions
func getIndegree(vertext: Int) -> Int
var numberOfVertices: Int { get set }
}
class Vertex {
let value: Int
var adjacencySet: Set<Int>
init(value: Int, adjacencySet: Set<Int>) {
self.value = value
self.adjacencySet = adjacencySet
}
func addEdge(vertext: Int) {
adjacencySet.insert(vertext)
}
func getAdjacentVertices() -> [Int] {
let array = Array(adjacencySet)
return array.sorted(by: { $0 < $1 })
}
}
Using Matrix
class AdjacencyMatrix: Graph {
var numberOfVertices: Int
private var matrix: [[Int]]
private let type: GraphType
init(vertices: [Int], graphType: GraphType) {
matrix = Array(
repeating: Array(
repeating: 0,
count: vertices.count
), count: vertices.count
)
numberOfVertices = vertices.count
type = graphType
}
func addEdge(src: Int, dst: Int) {
let range = 0..<numberOfVertices
guard range ~= src, range ~= dst else {
return
}
matrix[src][dst] = 1
if type == .undirected {
matrix[dst][src] = 1
}
}
func getAdjacentVertices(vertext: Int) -> [Int]? {
let range = 0..<numberOfVertices
guard range ~= vertext else {
return nil
}
var result = [Int]()
for i in 0..<numberOfVertices {
//If 1 is present in the cell it means that the vertext V is directly connected to another vertex
if matrix[vertext][i] == 1 {
result.append(i)
}
}
//Always return the vertices in ascending order - to compare with other values's adjacents
return result.sorted(by: { $0 < $1 })
}
//New function, Get Indegree of vertex
func getIndegree(vertext: Int) -> Int {
let range = 0..<numberOfVertices
guard range ~= vertext else {
return 0
}
var indegree = 0
//Loop from 0 to all vertex
for i in 0..<numberOfVertices {
//src = i, dst = vertex
if matrix[i][vertext] != 0 {
indegree += 1
}
}
return indegree
}
}
Topological Sort
func topologicalSort(graph: Graph) -> [Int] {
var queue = [Int]()
var indgreeMap = [Int: Int]()
//Step 1. Add first node of sort
for i in 0..<graph.numberOfVertices {
let indegree = graph.getIndegree(vertext: i)
//Add indegree 0's vertex to queue
indgreeMap[i] = indegree
//Add all vertices with indegree = 0 to the queue of vertices to explore
if indegree == 0 {
queue.append(i)
}
}
print(indgreeMap)
var result = [Int]()
//BFS
while !queue.isEmpty {
let vertex = queue.removeLast()
result.append(vertex)
var adjacentVertices = graph.getAdjacentVertices(vertext: vertex) ?? []
print("v: \(vertex) -> neighbors: \(adjacentVertices)")
for v in adjacentVertices {
//Important! get indegree from dictionary!
//Get the adjacent vertices of the current one and decrement their indegrees by 1
let updatedIndegree = indgreeMap[v]! - 1
indgreeMap[v] = updatedIndegree
//For every vertex which now has indegree = 0, It's a potential next node for the topological sort
if updatedIndegree == 0 {
queue.append(v)
}
}
}
print(result)
//If the final sorted list is not same to the number of vertices in the graph there is a cycles
if result.count != graph.numberOfVertices {
print("There is cycle")
return []
}
return result
}
class GraphAdjacencySet: Graph {
var vertices: [Vertex]
let graphType: GraphType
var numberOfVertices: Int
init(numberOfVertices: Int, graphType: GraphType) {
self.vertices = [Vertex]()
for i in 0..<numberOfVertices {
vertices.append(Vertex(value: i, adjacencySet: []))
}
self.numberOfVertices = numberOfVertices
self.graphType = graphType
}
func addEdge(src: Int, dst: Int) {
let range = 0..<numberOfVertices
guard range ~= src, range ~= dst else {
return
}
vertices[src].addEdge(vertext: dst)
if graphType == .undirected {
vertices[dst].addEdge(vertext: src)
}
}
func getAdjacentVertices(vertext: Int) -> [Int]? {
let range = 0..<numberOfVertices
guard range ~= vertext else {
return nil
}
return vertices[vertext].getAdjacentVertices()
}
//New function, Get Indegree of vertex
func getIndegree(vertext: Int) -> Int {
let range = 0..<numberOfVertices
guard range ~= vertext else {
return 0
}
var indegree = 0
//Loop from 0 to all vertex
for i in 0..<numberOfVertices {
if getAdjacentVertices(vertext: i)?.contains(vertext) == true {
indegree += 1
}
}
return indegree
}
}
All nodes with indegree 0 are potential courses the student could start with
There are many schedules possible!
func courseOrder(courseList: [Int], prereqs: [Int: [Int]]) {
let graph = AdjacencyMatrix(vertices: courseList, graphType: .directed)
//You need this because Matrix used row and col start from 0 to number of vertices.
var courseId = [Int: Int]()
var matrixIndexToCourseId = [Int: Int]()
for (index, course) in courseList.enumerated() {
courseId[course] = index
matrixIndexToCourseId[index] = course
}
//Link Edges
for (preCourse, nextCourse) in prereqs {
for next in nextCourse {
print("add edge: \(preCourse) -> \(next)")
let preCourseId = courseId[preCourse]
let nextId = courseId[next]
graph.addEdge(src: preCourseId!, dst: nextId!)
}
}
var indegreeMap = [Int: Int]()
//Int is courseId not a Index
var queue = [Int]()
var sorted = [Int]()
for v in courseList {
//VertextId will be 0..<numberOfVertices
let vertexId = courseId[v]!
let indegree = graph.getIndegree(vertext: vertexId)
indegreeMap[v] = indegree
//Can take this course
if indegree == 0 {
queue.append(v)
}
}
print(indegreeMap)
while !queue.isEmpty {
let insertingCourse = queue.removeFirst()
sorted.append(insertingCourse)
let vertexId = courseId[insertingCourse]!
let nextCourses = graph.getAdjacentVertices(vertext: vertexId) ?? []
for nextCourse in nextCourses {
let courseId = matrixIndexToCourseId[nextCourse]!
let updatedIndegree = indegreeMap[courseId]! - 1
indegreeMap[courseId] = updatedIndegree
print("Next course: \(courseId) - Indegree: \(updatedIndegree)")
if updatedIndegree == 0 {
queue.append(courseId)
}
}
}
print(sorted)
}
courseOrder(
courseList: [101, 102, 103, 104, 105, 106, 107],
prereqs: [101: [102, 103, 105], 104: [105], 105: [107]]
)
Some codes and contents are sourced from Udemy. This post is for personal notes where I summarize the original contents to grasp the key concepts(🎨 some images I draw it)
Priority Queue
When a certain element in a collection has the highest weightage or priority – A common use case is to process that First
The data structure you use to store elements where the highest priority has to be processed first can be called a priority queue
At every step we access the element with the highest priority
The data structure needs to understand the priorities of the elements it holds
Common Operations
Insertelements (along with priority information)
Access the highest priority element
Remove the highest priority element
Use cases
Event simulation, Thread scheduling
Implementation
Case 1. Use an Array or List
Unordered
Insertion
Can be anywhere in the list or array – O(1)
Access
Accessing the highest priority element requires going through all elements in the List – O(N)
Remove
Removing the highest priority element requires going through all elements in the list – O(N)
Ordered
Insertion
Requires finding the right position for the element based on priority – O(N)
Access
Accessing the highest priority element is then easy – O(1)
Remove
Removing the highest priority element is straightforward – O(1)
Case 2. Balanced Binary Search Tree – All operations are O(LogN)
Insertion
Worst Case – O(LogN)
Access
Accessing the highest priority element is again O(LogN)
Remove
O(LogN)
Case 3. Binary Heap is the best for implementing Priority Queue
All nodes at Level H-1 nodes (9, 12, 11, 7) have to be filled before moving on to level H
Implementation
Logical structure of a binary heap is a Tree
Each node would have a pointer to the left and right child
Traverse
Traverse downwards from the root towards the leaf nodes
Traverse upward from the leaf nodes towards the root
Operations
Get left child
Get right child
Get parent
Heaps can be represented much more efficiently by using an array and having an implicit relationship to determine the parent, left and right child of a node
Every level of the binary tree in a heap is filled except perhaps the last
This means contiguous slots in an array can be used to represent binary tree levels
class MaxHeap<T: Comparable>: Heap {
var array: [T?]
var count: Int
required init(_ input: [T]) {
self.array = input
self.count = input.count
}
//Recursive call
func siftDown(index: Int) {
let leftChildIndex = leftChildIndex(index: index)
let rightChildIndex = rightChildIndex(index: index)
//smaller value in chids
var swapCandidateIndex: Int?
if leftChildIndex != nil, rightChildIndex != nil {
if array[leftChildIndex!]! > array[rightChildIndex!]! {
swapCandidateIndex = leftChildIndex
}
else {
swapCandidateIndex = rightChildIndex
}
}
else if leftChildIndex != nil {
swapCandidateIndex = leftChildIndex
}
else if rightChildIndex != nil {
swapCandidateIndex = rightChildIndex
}
//Base case
guard let swapCandidateIndex, let swapCandidateValue = array[swapCandidateIndex], let currentIndexValue = array[index] else {
return
}
if currentIndexValue > swapCandidateValue {
let value = array[swapCandidateIndex]
//Sift down small value to the next level
array[swapCandidateIndex] = currentIndexValue
array[index] = swapCandidateValue
//Recursive Call
siftDown(index: swapCandidateIndex)
}
}
func siftUp(index: Int) {
guard let parentIndex = parentIndex(index: index), let currentValue = array[index] else {
return
}
if array[parentIndex]! < currentValue {
let parentValue = array[parentIndex]!
array[parentIndex] = currentValue
array[index] = parentValue
siftUp(index: parentIndex)
}
}
func insert(value: Item) {
array.append(value)
count = array.count
let insertedIndex = array.count - 1
siftUp(index: insertedIndex)
}
func removeHighestPriority() -> T? {
let root = array[0]
let lastElement = array[array.count - 1]
array.removeFirst()
array.insert(lastElement, at: 0)
siftDown(index: 0)
return root
}
//Heapify the entire array
func heapify(index: Int) {
//Start with the parent index of the last element
guard var parentIndex = parentIndex(index: index) else {
return
}
while parentIndex >= 0 {
percolateDown(index: parentIndex)
parentIndex -= 1
}
}
func percolateDown(index: Int) {
let leftIndex = leftChildIndex(index: index)
let rightIndex = rightChildIndex(index: index)
//Check If the max heap property is satisfied
if let leftIndex, array[leftIndex]! > array[index]! {
let currentValue = array[index]!
let leftChildValue = array[leftIndex]!
array[index] = leftChildValue
array[leftIndex] = currentValue
percolateDown(index: leftIndex)
}
if let rightIndex, array[rightIndex]! > array[index]! {
let currentValue = array[index]!
let rightChildValue = array[rightIndex]!
array[index] = rightChildValue
array[rightIndex] = currentValue
percolateDown(index: rightIndex)
}
}
}
let input = [4, 6, 9, 2, 10, 56, 12, 5, 1, 17, 14]
let maxHeap = MaxHeap(input)
maxHeap.heapify(index: input.count - 1)
print(maxHeap.array)
Heap Sort – Heap to Sorted Array
Full source – (This code has updated previous example)
protocol Heap {
associatedtype Item: Comparable
var array: [Item?] { get set }
var count: Int { get set }
init(_ input: [Item])
func leftChildIndex(index: Int, endIndex: Int) -> Int?
func rightChildIndex(index: Int, endIndex: Int) -> Int?
func parentIndex(index: Int, endIndex: Int) -> Int?
func siftDown(index: Int)
func siftUp(index: Int)
func insert(value: Item)
func removeHighestPriority() -> Item?
}
extension Heap {
func leftChildIndex(index: Int, endIndex: Int) -> Int? {
let leftIndex = 2 * index + 1
if leftIndex > endIndex {
return nil
}
return leftIndex
}
func rightChildIndex(index: Int, endIndex: Int) -> Int? {
let rightIndex = 2 * index + 2
if rightIndex > endIndex {
return nil
}
return rightIndex
}
func parentIndex(index: Int, endIndex: Int) -> Int? {
if index < 0 || index > endIndex {
return nil
}
return (index - 1) / 2
}
//MARK: Helper functions
var isFull: Bool {
count == array.count
}
}
class MinHeap<T: Comparable>: Heap {
var array: [T?]
var count: Int
required init(_ input: [T]) {
self.array = input
self.count = input.count
}
//Recursive call
func siftDown(index: Int) {
let leftChildIndex = leftChildIndex(index: index, endIndex: count)
let rightChildIndex = rightChildIndex(index: index, endIndex: count)
//smaller value in chids
var swapCandidateIndex: Int?
if leftChildIndex != nil, rightChildIndex != nil {
if array[leftChildIndex!]! < array[rightChildIndex!]! {
swapCandidateIndex = leftChildIndex
}
else {
swapCandidateIndex = rightChildIndex
}
}
else if leftChildIndex != nil {
swapCandidateIndex = leftChildIndex
}
else if rightChildIndex != nil {
swapCandidateIndex = rightChildIndex
}
//Base case
guard let swapCandidateIndex, let swapCandidateValue = array[swapCandidateIndex], let currentIndexValue = array[index] else {
return
}
if currentIndexValue > swapCandidateValue {
let value = array[swapCandidateIndex]
//Sift down large value to the next level
array[swapCandidateIndex] = currentIndexValue
array[index] = swapCandidateValue
//Recursive Call
siftDown(index: swapCandidateIndex)
}
}
func siftUp(index: Int) {
guard let parentIndex = parentIndex(index: index, endIndex: count), let currentValue = array[index] else {
return
}
if array[parentIndex]! > currentValue {
let parentValue = array[parentIndex]!
array[parentIndex] = currentValue
array[index] = parentValue
siftUp(index: parentIndex)
}
}
func insert(value: Item) {
array.append(value)
count = array.count
let insertedIndex = array.count - 1
siftUp(index: insertedIndex)
}
func removeHighestPriority() -> T? {
let root = array[0]
let lastElement = array[array.count - 1]
array.removeFirst()
array.insert(lastElement, at: 0)
siftDown(index: 0)
return root
}
}
class MaxHeap<T: Comparable>: Heap {
var array: [T?]
var count: Int
required init(_ input: [T]) {
self.array = input
self.count = input.count
}
//Recursive call
func siftDown(index: Int) {
let leftChildIndex = leftChildIndex(index: index, endIndex: count)
let rightChildIndex = rightChildIndex(index: index, endIndex: count)
//smaller value in chids
var swapCandidateIndex: Int?
if leftChildIndex != nil, rightChildIndex != nil {
if array[leftChildIndex!]! > array[rightChildIndex!]! {
swapCandidateIndex = leftChildIndex
}
else {
swapCandidateIndex = rightChildIndex
}
}
else if leftChildIndex != nil {
swapCandidateIndex = leftChildIndex
}
else if rightChildIndex != nil {
swapCandidateIndex = rightChildIndex
}
//Base case
guard let swapCandidateIndex, let swapCandidateValue = array[swapCandidateIndex], let currentIndexValue = array[index] else {
return
}
if currentIndexValue > swapCandidateValue {
let value = array[swapCandidateIndex]
//Sift down small value to the next level
array[swapCandidateIndex] = currentIndexValue
array[index] = swapCandidateValue
//Recursive Call
siftDown(index: swapCandidateIndex)
}
}
func siftUp(index: Int) {
guard let parentIndex = parentIndex(index: index, endIndex: count), let currentValue = array[index] else {
return
}
if array[parentIndex]! < currentValue {
let parentValue = array[parentIndex]!
array[parentIndex] = currentValue
array[index] = parentValue
siftUp(index: parentIndex)
}
}
func insert(value: Item) {
array.append(value)
count = array.count
let insertedIndex = array.count - 1
siftUp(index: insertedIndex)
}
func removeHighestPriority() -> T? {
let root = array[0]
let lastElement = array[array.count - 1]
array.removeFirst()
array.insert(lastElement, at: 0)
siftDown(index: 0)
return root
}
//Heapify the entire array
func heapify(index: Int) {
//Start with the parent index of the last element
guard var parentIndex = parentIndex(index: index, endIndex: index) else {
return
}
while parentIndex >= 0 {
percolateDown(index: parentIndex, endIndex: index)
parentIndex -= 1
}
}
func percolateDown(index: Int, endIndex: Int) {
let leftIndex = leftChildIndex(index: index, endIndex: endIndex)
let rightIndex = rightChildIndex(index: index, endIndex: endIndex)
//Check If the max heap property is satisfied
if let leftIndex, array[leftIndex]! > array[index]! {
let currentValue = array[index]!
let leftChildValue = array[leftIndex]!
array[index] = leftChildValue
array[leftIndex] = currentValue
percolateDown(index: leftIndex, endIndex: endIndex)
}
if let rightIndex, array[rightIndex]! > array[index]! {
let currentValue = array[index]!
let rightChildValue = array[rightIndex]!
array[index] = rightChildValue
array[rightIndex] = currentValue
percolateDown(index: rightIndex, endIndex: endIndex)
}
}
func heapSort() {
//Heapify! The entire unsorted array so It's now a Heap
heapify(index: array.count - 1)
var lastIndex = array.count - 1
while lastIndex > 0 {
let maxValue = array[0]!
let currentValue = array[lastIndex]!
//Swap - Start with the very last index, and place the largest element in the last position
array[0] = currentValue
array[lastIndex] = maxValue
//Count down because last element already sorted
lastIndex -= 1
percolateDown(index: 0, endIndex: lastIndex)
}
}
}
let input = [4, 6, 9, 2, 10, 56, 12, 5, 1, 17, 14]
let maxHeap = MaxHeap(input)
print("Heapify - Make unordered input to maxHeap: ")
maxHeap.heapify(index: input.count - 1)
print(maxHeap.array)
maxHeap.heapSort()
print("\nHeap Sort!: ")
print(maxHeap.array)
Heap Sort
Heap sort uses operations on a heap to get a sorted list
Insertion into a heap is done N times to get all the elements in heap form
Removal of the maximum element is done N times, followed by Heapify
Insertion and removal have log N time complexity so doing it for N elements means
The average case complexity of heap sort is O(nLogN)
Heap sort is not adaptive – If works on almost sorted array it’s not a fast because there is no way to break up early.
It’s not a stable sort – If there is 2 same value.. that order is not maintain in heap sort. It means 2 same value can’t guarantee orders. (But heap sort can handle if there are same values) see stackoverflow
It does not need additional space – Space complexity is O(1)
My example codes for Heap Structure is not the same. Some exercise I used the fixed array using maxSize. The others are not. Please check full source code at each exercise.
Exercise 1. Find the maximum element in a minimum heap
class MinHeap<T: Comparable>: Heap {
var array: [T?]
var count: Int
required init(_ input: [T]) {
self.array = input
self.count = input.count
}
//Recursive call
func siftDown(index: Int) {
let leftChildIndex = leftChildIndex(index: index, endIndex: count)
let rightChildIndex = rightChildIndex(index: index, endIndex: count)
//smaller value in chids
var swapCandidateIndex: Int?
if leftChildIndex != nil, rightChildIndex != nil {
if array[leftChildIndex!]! < array[rightChildIndex!]! {
swapCandidateIndex = leftChildIndex
}
else {
swapCandidateIndex = rightChildIndex
}
}
else if leftChildIndex != nil {
swapCandidateIndex = leftChildIndex
}
else if rightChildIndex != nil {
swapCandidateIndex = rightChildIndex
}
//Base case
guard let swapCandidateIndex, let swapCandidateValue = array[swapCandidateIndex], let currentIndexValue = array[index] else {
return
}
if currentIndexValue > swapCandidateValue {
let value = array[swapCandidateIndex]
//Sift down large value to the next level
array[swapCandidateIndex] = currentIndexValue
array[index] = swapCandidateValue
//Recursive Call
siftDown(index: swapCandidateIndex)
}
}
func siftUp(index: Int) {
guard let parentIndex = parentIndex(index: index, endIndex: count), let currentValue = array[index] else {
return
}
if array[parentIndex]! > currentValue {
let parentValue = array[parentIndex]!
array[parentIndex] = currentValue
array[index] = parentValue
siftUp(index: parentIndex)
}
}
func insert(value: Item) {
array.append(value)
count = array.count
let insertedIndex = array.count - 1
siftUp(index: insertedIndex)
}
func removeHighestPriority() -> T? {
let root = array[0]
let lastElement = array[array.count - 1]
array.removeFirst()
array.insert(lastElement, at: 0)
siftDown(index: 0)
return root
}
//Heapify the entire array
func heapify(index: Int) {
//Start with the parent index of the last element
guard var parentIndex = parentIndex(index: index, endIndex: index) else {
return
}
while parentIndex >= 0 {
percolateDown(index: parentIndex, endIndex: index)
parentIndex -= 1
}
}
func percolateDown(index: Int, endIndex: Int) {
let leftIndex = leftChildIndex(index: index, endIndex: endIndex)
let rightIndex = rightChildIndex(index: index, endIndex: endIndex)
//Check If the max heap property is satisfied
if let leftIndex, array[leftIndex]! < array[index]! {
let currentValue = array[index]!
let leftChildValue = array[leftIndex]!
array[index] = leftChildValue
array[leftIndex] = currentValue
percolateDown(index: leftIndex, endIndex: endIndex)
}
if let rightIndex, array[rightIndex]! < array[index]! {
let currentValue = array[index]!
let rightChildValue = array[rightIndex]!
array[index] = rightChildValue
array[rightIndex] = currentValue
percolateDown(index: rightIndex, endIndex: endIndex)
}
}
func maxValue() -> T? {
let lastIndex = array.count - 1
guard let parentIndex = parentIndex(index: lastIndex, endIndex: array.count - 1), var maxValue = array[parentIndex + 1] else {
return nil
}
//maxValue is first leaf node
let firstLeafIndex = parentIndex + 1
for i in firstLeafIndex..<array.count {
maxValue = max(array[i]!, maxValue)
}
return maxValue
}
}
let input = [4, 6, 9, 2, 10, 56, 12, 5, 1, 17, 14]
let minHeap = MinHeap(input)
print("Heapify - Make unordered input to maxHeap: ")
minHeap.heapify(index: input.count - 1)
print(minHeap.array)
print("🟢 Max Value in MinHeap: \(minHeap.maxValue())")
Exercise 2. Find K Largest Elements in a Stream
Stream can be events from external sources. It is not a sorted
Use a minimum heap with size K to store elements as they come in
The top of the heap will have the smallest of the K elements stored in the heap
If the new elements in the stream is larger than the minimum – add it to the heap
The heap will always have the largest K elements from the stream
You can use array and sort items when insert value. Let’s call it FakeHeap!
FakeHeap source code
class FakeMinHeap {
var array: [Int?]
let maxSize: Int?
init(maxSize: Int?) {
self.maxSize = maxSize
if let maxSize {
array = Array(repeating: nil, count: maxSize)
}
else {
array = [Int?]()
}
}
var count: Int {
array.count
}
func insert(value: Int) {
array.append(value)
array = array.compactMap { $0 }.sorted(by: <)
}
func highestPriority() -> Int? {
return array.first ?? nil
}
func removeHighestPriority() -> Int? {
return array.removeFirst()
}
}
class FakeMaxHeap {
var array: [Int?]
let maxSize: Int?
init(maxSize: Int?) {
self.maxSize = maxSize
if let maxSize {
array = Array(repeating: nil, count: maxSize)
}
else {
array = [Int?]()
}
}
var count: Int {
array.count
}
func insert(value: Int) {
array.append(value)
array = array.compactMap { $0 }.sorted(by: >)
}
func highestPriority() -> Int? {
return array.first ?? nil
}
func removeHighestPriority() -> Int? {
return array.removeFirst()
}
}
let minHeap = FakeMinHeap(maxSize: nil)
let maxHeap = FakeMaxHeap(maxSize: nil)
Let’s test last exercise. Find the median in a stream of elements using FakeHeap!
let minHeap = FakeMinHeap(maxSize: nil)
let maxHeap = FakeMaxHeap(maxSize: nil)
func getMedianValue(input: Int) -> Int {
if maxHeap.count != 0, let maxValue = maxHeap.highestPriority(), input > maxValue {
minHeap.insert(value: input)
print("Insert \(input) > \(maxValue) to MinHeap")
}
else {
maxHeap.insert(value: input)
print("Insert \(input) to MaxHeap")
}
//Check rebalance - Difference is greater 1
if maxHeap.count > minHeap.count, maxHeap.count - minHeap.count > 1, let _ = maxHeap.highestPriority() {
let removedMaxValue = maxHeap.removeHighestPriority()!
minHeap.insert(value: removedMaxValue)
print("✅ Rebalanced - Insert removed: \(removedMaxValue) to MinHeap")
}
else if minHeap.count > maxHeap.count, minHeap.count - maxHeap.count > 1, let minValue = minHeap.highestPriority() {
let removedMinValue = minHeap.removeHighestPriority()!
maxHeap.insert(value: removedMinValue)
print("✅ Rebalanced - Insert removed: \(removedMinValue) to MaxHeap")
}
if minHeap.count == maxHeap.count {
return (minHeap.highestPriority()! + maxHeap.highestPriority()!) / 2
}
return minHeap.count > maxHeap.count ? minHeap.highestPriority()! : maxHeap.highestPriority()!
}
let input = [5, 6, 7, 9, 10, 2, 3, 13, 15, 17, 20, 1, 8]
for i in input {
getMedianValue(input: i)
}
print("MinHeap: \(minHeap.array)")
print("MaxHeap: \(maxHeap.array)")
As you can see, result is the same as Real Heap. (Absolutely time complexity is different compare with real heap data structure, because It’s fake heap to solve problem during the interview)
Some codes and contents are sourced from Apple’s official documentation. This post is for personal notes where I summarize the original contents to grasp the key concepts
What is Autorelease Pool?
An object that supports Cocoa’s reference-counted memory management system.
An autorelease pool stores objects that are sent a release messagewhen the pool itself is drained.
If you use Automatic Reference Counting (ARC), you cannot use autorelease pools directly. Instead, you use @autoreleasepool blocks.
@autoreleasepool blocks are more efficient than using an instance of NSAutoreleasePool directly; you can also use them even if you do not use ARC.
You can send multiple autorelease message to an object. When autorelease pool released, object will receive multiple release message.
Common Scenario when Is it useful for? -> Created an object in a Loop!
for (i=0; i < MANY_TIMES; i++)
{
NSAutoreleasePool *pool = [[NSAutoreleasePool alloc] init];
//Create an object and send autorelease message
MyObject *object = [[MyObject alloc] init];
[object autorelease];
//Release all objects that created in this loop.
[pool release];
}
Some codes and contents are sourced from Apple’s official documentation. This post is for personal notes where I summarize the original contents to grasp the key concepts(🎨 some images I draw it)
About the iOS File System
For security purposes, an iOS app’s interactions with the file system are limited to the directories inside the app’s sandbox directory. During installation of a new app, the installer creates a number of container directories for the app inside the sandbox directory. Each container directory has a specific role. The bundle container directory holds the app’s bundle, whereas the data container directory holds data for both the app and the user. The data container directory is further divided into a number of subdirectories that the app can use to sort and organize its data. The app may also request access to additional container directories—for example, the iCloud container—at runtime.
These container directories constitute the app’s primary view of the file system. Figure 1-1 shows a representation of the sandbox directory for an app.
An app is generallyprohibited from accessing or creating files outside its container directories.One exception to this rule is when an app uses public system interfaces to access things such as the user’s contacts or music. In those cases, the system frameworks use helper apps to handle any file-related operations needed to read from or modify the appropriate data stores.
To prevent the syncing and backup processes on iOS devices from taking a long time, be selective about where you place files. Apps that store large files can slow down the process of backing up to iTunes or iCloud. These apps can also consume a large amount of a user’s available storage, which may encourage the user to delete the app or disable backup of that app’s data to iCloud. With this in mind, you should store app data according to the following guidelines:
Put user data in Documents/. User data generally includes any files you might want to expose to the user—anything you might want the user to create, import, delete or edit. For a drawing app, user data includes any graphic files the user might create. For a text editor, it includes the text files. Video and audio apps may even include files that the user has downloaded to watch or listen to later.
Put app-created support files in the Library/Application support/ directory. In general, this directory includes files that the app uses to run but that should remain hidden from the user. This directory can also include data files, configuration files, templates and modified versions of resources loaded from the app bundle.
Remember that files in Documents/ and Application Support/ are backed up by default. You can exclude files from the backup by calling -[NSURL setResourceValue:forKey:error:] using the NSURLIsExcludedFromBackupKey key. Any file that can be re-created or downloaded must be excluded from the backup. This is particularly important for large media files. If your application downloads video or audio files, make sure they are not included in the backup.
Put temporary data in the tmp/ directory. Temporary data comprises any data that you do not need to persist for an extended period of time. Remember to delete those files when you are done with them so that they do not continue to consume space on the user’s device. The system will periodically purge these files when your app is not running; therefore, you cannot rely on these files persisting after your app terminates.
Put data cache files in the Library/Caches/ directory. Cache data can be used for any data that needs to persist longer than temporary data, but not as long as a support file. Generally speaking, the application does not require cache data to operate properly, but it can use cache data to improve performance. Examples of cache data include (but are not limited to) database cache files and transient, downloadable content. Note that the system may delete the Caches/ directory to free up disk space, so your app must be able to re-create or download these files as needed.
This directory contains app-specific preference files. You should not create files in this directory yourself. Instead, use the NSUserDefaults class or CFPreferences API to get and set preference values for your app. In iOS, the contents of this directory are backed up by iTunes and iCloud.
iCloud provides a structured system for storing files for apps that make use of iCloud:
Apps have a primary iCloud container directory for storing their native files. They can also access secondary iCloud container directories listed in their app entitlements.
Inside each container directory, files are segregated into “documents” and data. Every file or file package located in the Documentssubdirectory (or one of its subdirectories) is presented to the user (via the iCloud UI in macOS and iOS) as a separate document that can be deleted individually. Anything not in Documents or one of its subdirectories is treated as data and shown as a single entry in the iCloud UI.
Documents that the user creates and sees in an app’s user interface—for example the document browsers in Pages, Numbers, and Keynote should be stored in the Documents directory. Another example of files that might go in the Documents directory are saved games, again because they are something that an app could potentially provide some sort of method for selecting.
Anything that the app does not want the user to see or modify directly should be placed outside of the Documents directory. Apps can create any subdirectories inside the container directory, so they can arrange private files as desired.
Apps create files and directories in iCloud container directories in exactly the same way as they create local files and directories. And all the file’s attributes are saved, if they add extended attributes to a file, those attributes are copied to iCloud and to the user’s other devices too.
iCloud containers also allow the storage of key-value pairs that can be easily accessed without having to create a document format.
Sandboxes prevent apps from writing to parts of the file system that they should not write to. Each sandboxed app receives one or more containers that it can write into. An app cannot write to other apps’ containers or to most directories outside of the sandbox. These restrictions limit the potential damage that can be done in the event that an app’s security is breached.
iOS apps always run in a sandbox, the system assigns specific ACLs and permissions to files created by each app.
iOS. An iOS app can designate files that it wants to be encrypted on disk. When the user unlocks a device containing encrypted files, the system creates a decryption key that allows the app to access its encrypted files. When the user locks the device, though, the decryption key is destroyed to prevent unauthorized access to the files.
in iOS, apps that take advantage of disk-based encryption need to be discontinue the use of encrypted files when the user locks the device. Because locking the device destroys the decryption keys, access to encrypted files is limited to when the device is unlocked. If your iOS app can run in the background while the device is locked, it must do so without access to any of its encrypted files. Because encrypted disks in macOS are always accessible while the computer is running, macOS apps do not need to do anything special to handle disk-level encryption.
Because file-related operations involve interacting with the hard disk and are therefore slow compared to most other operations, most of the file-related interfaces in iOS and macOS are designed with concurrency in mind. Several technologies incorporate asynchronous operation into their design and most others can execute safely from a dispatch queue or secondary thread. Table 1-4 lists some of the key technologies discussed in this document and whether they are safe to use from specific threads or any thread. For specific information about the capabilities of any interface, see the reference documentation for that interface.
Even if you use an thread-safe interface for manipulating a file, problems can still arise when multiple threads or multiple processes attempt to act on the same file. Although there are safeguards to prevent multiple clients from modifying a file at the same time, those safeguards do not always guarantee exclusive access to the file at all times. (Nor should you attempt to prevent other processes from accessing shared files.) To make sure your code knows about changes made to shared files, use file coordinators to manage access to those files. For more information about file coordinators, see The Role of File Coordinators and Presenters














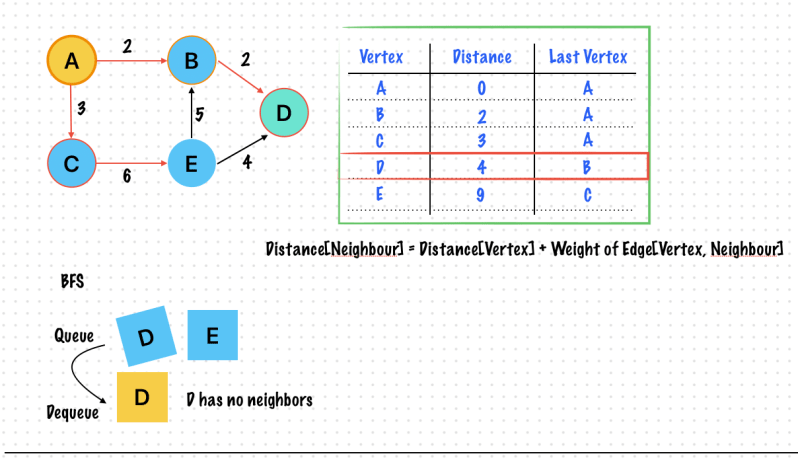
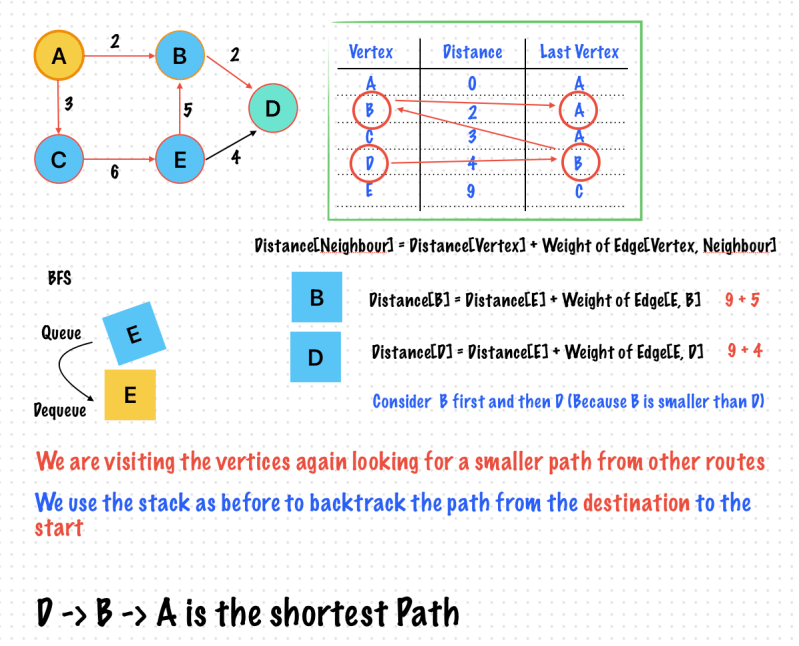










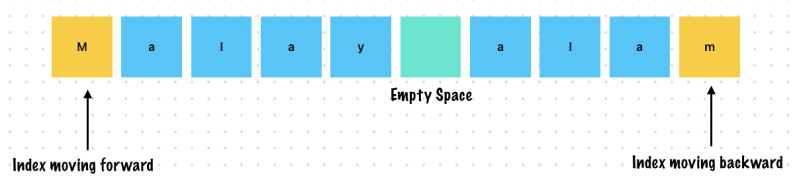

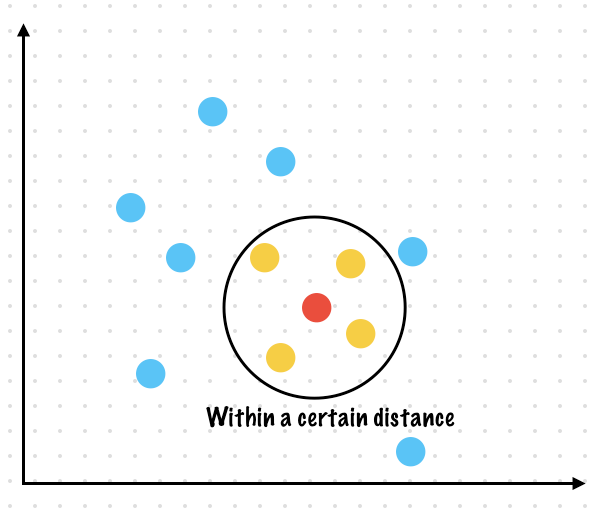



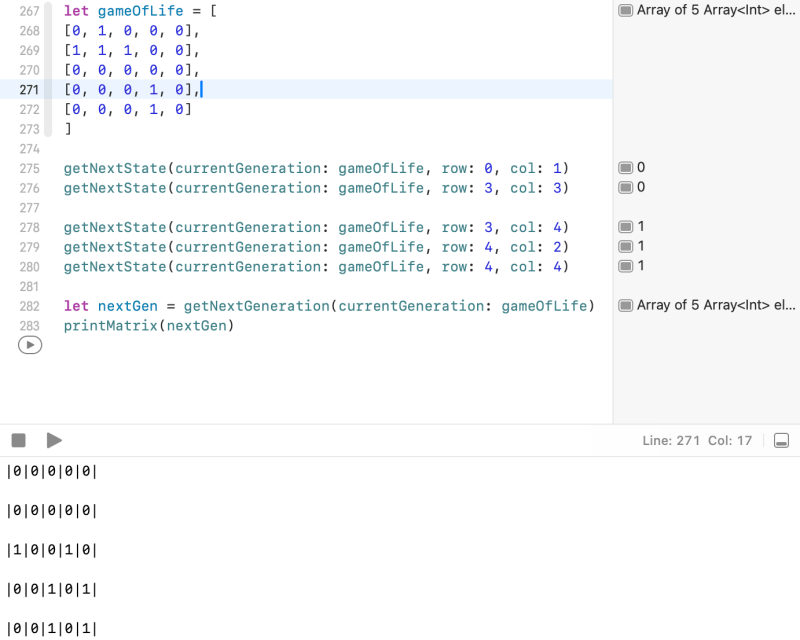
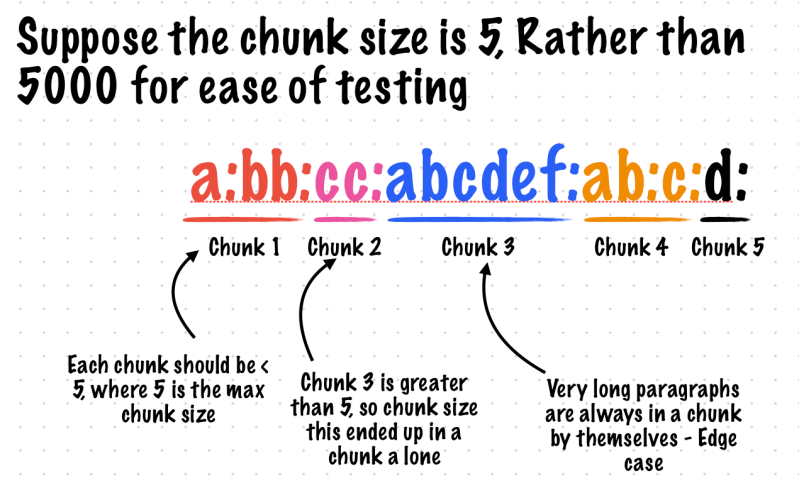
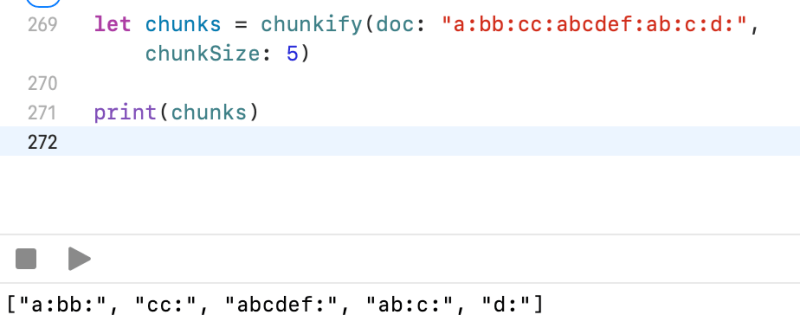




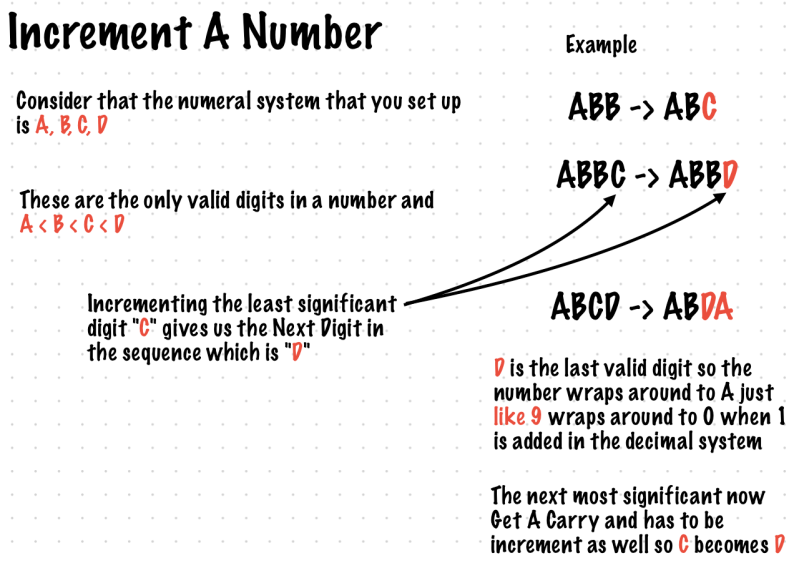




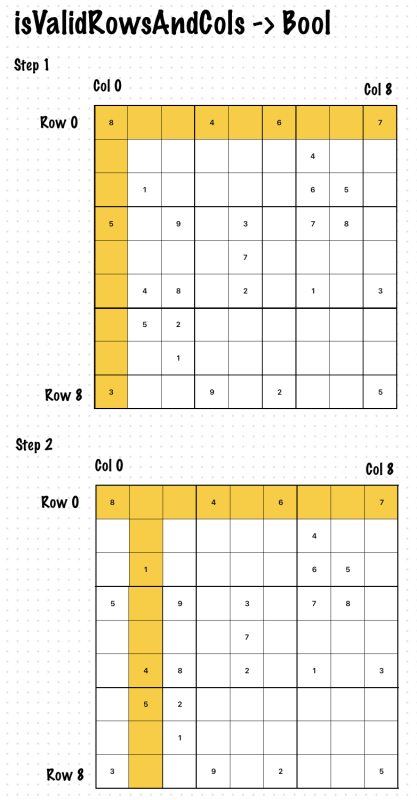

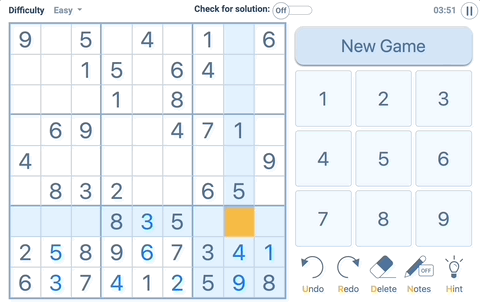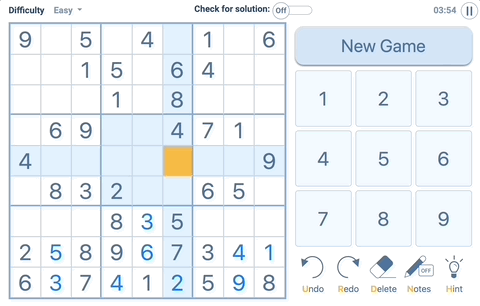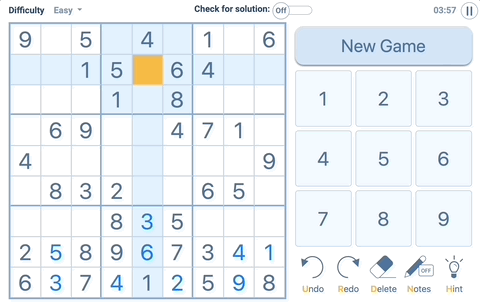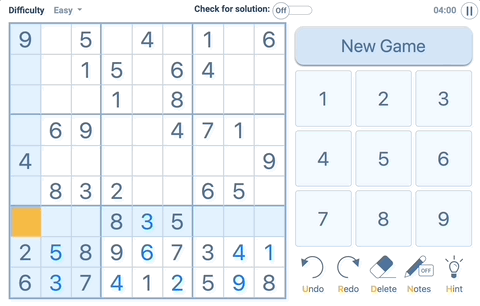




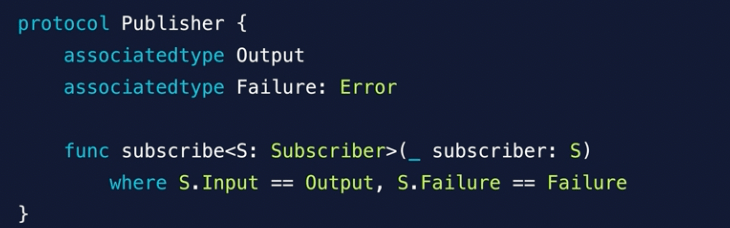
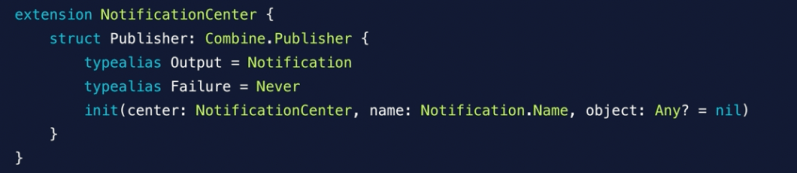
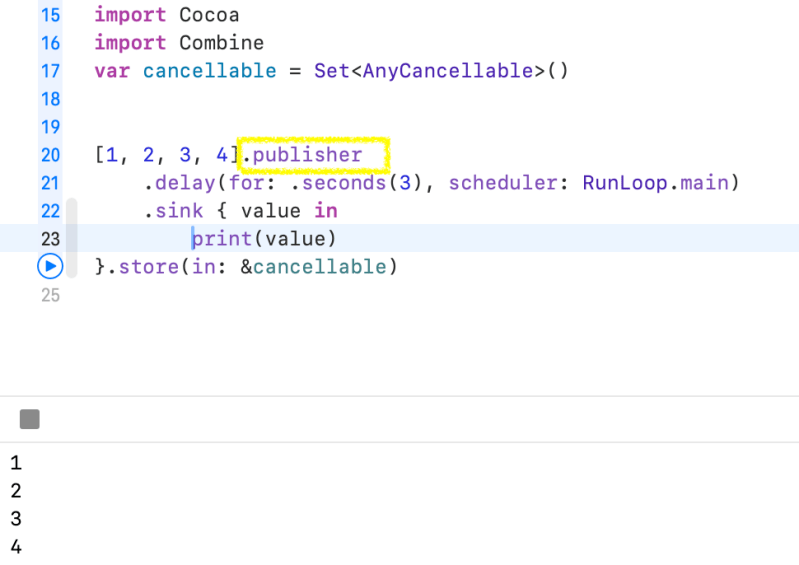
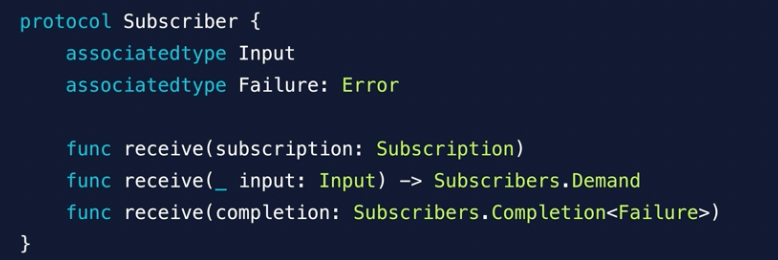

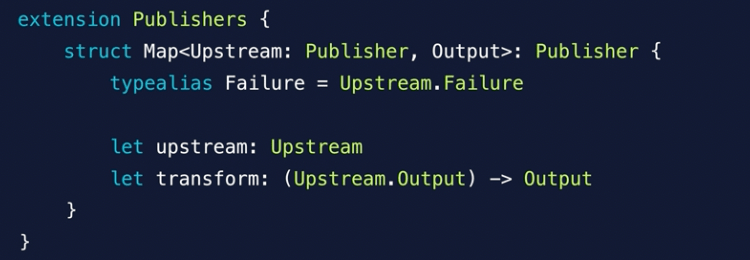

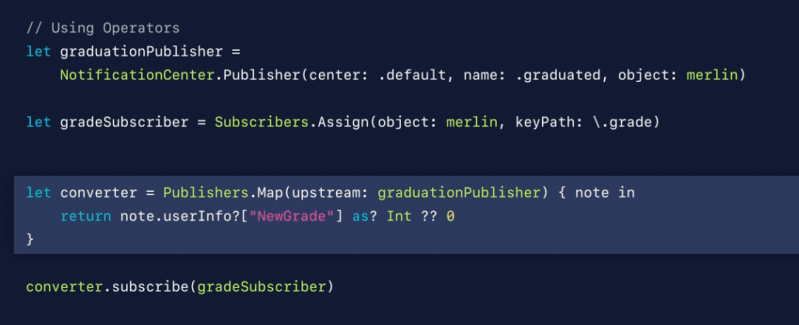
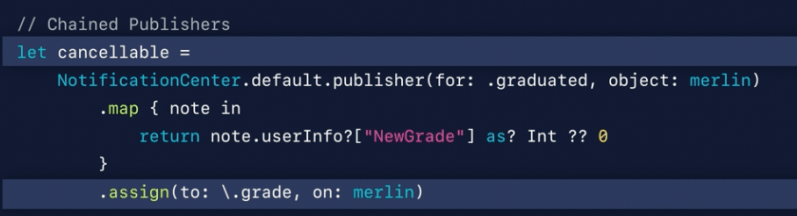

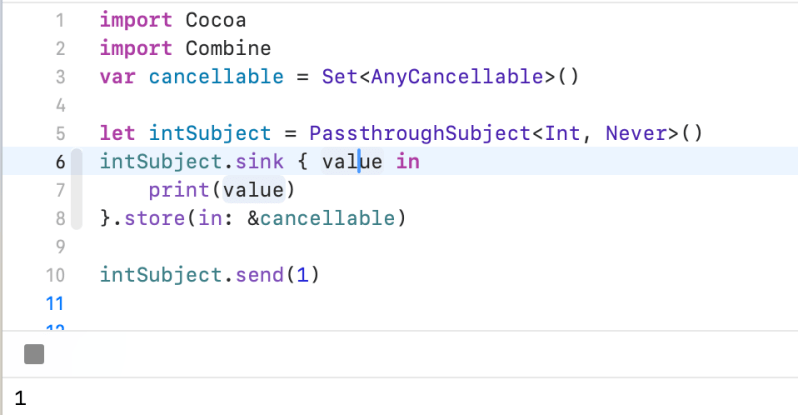
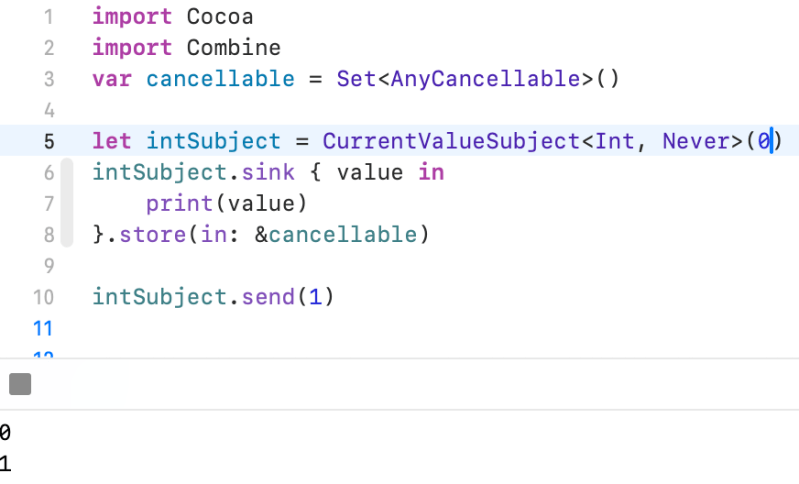
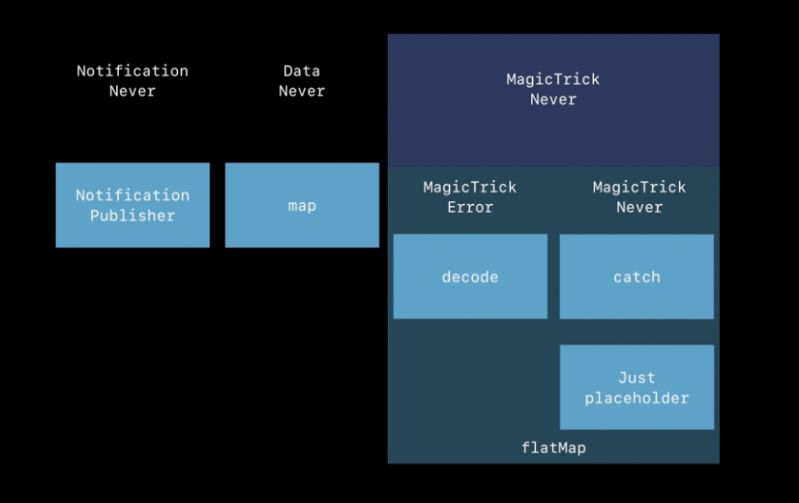
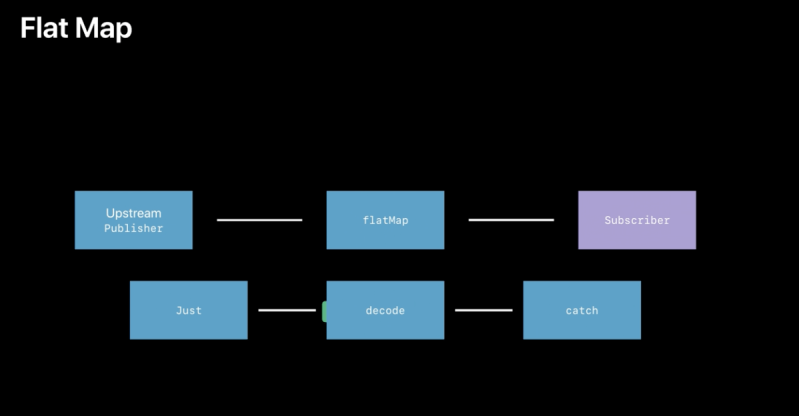
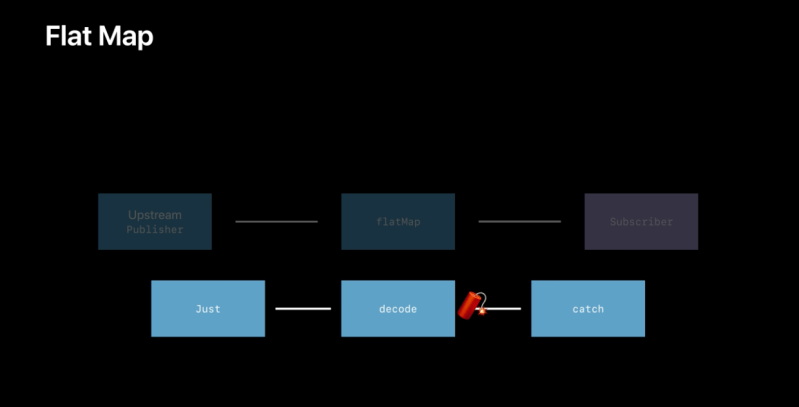
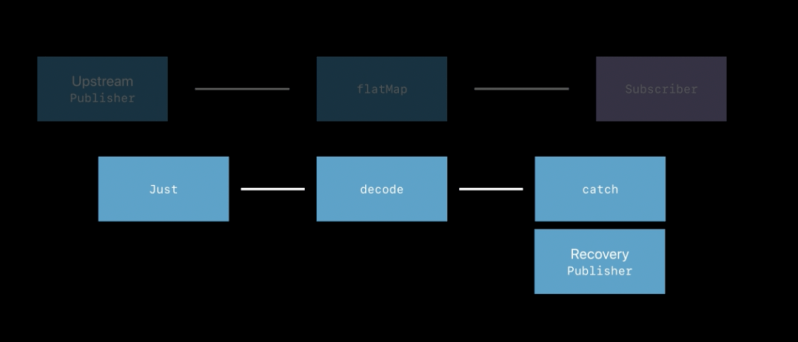
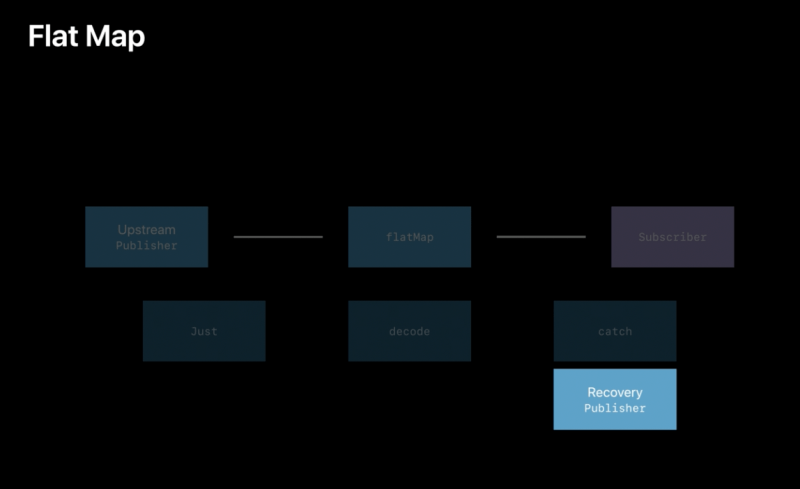
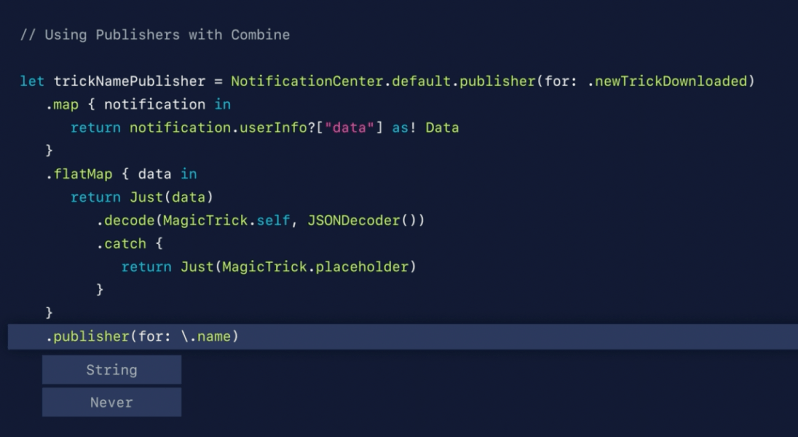
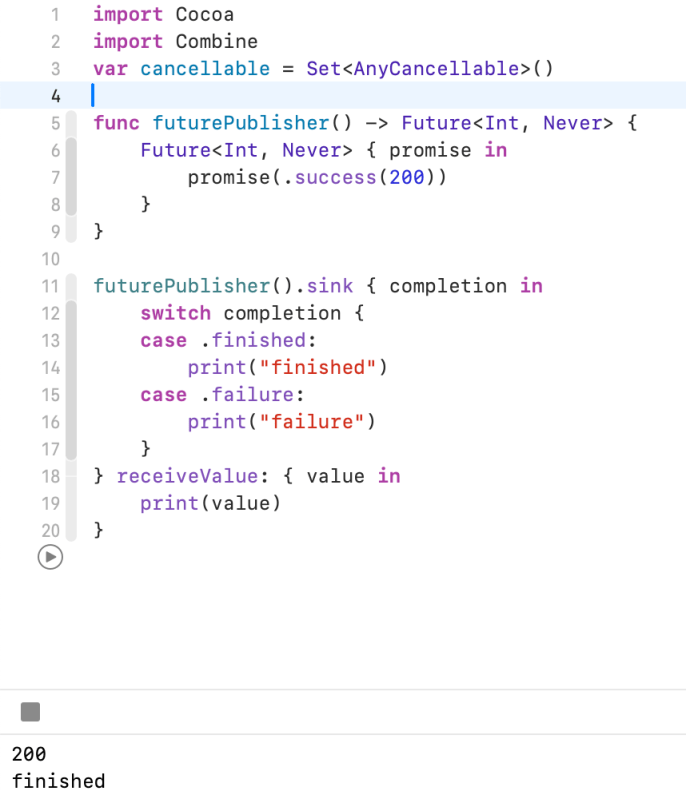
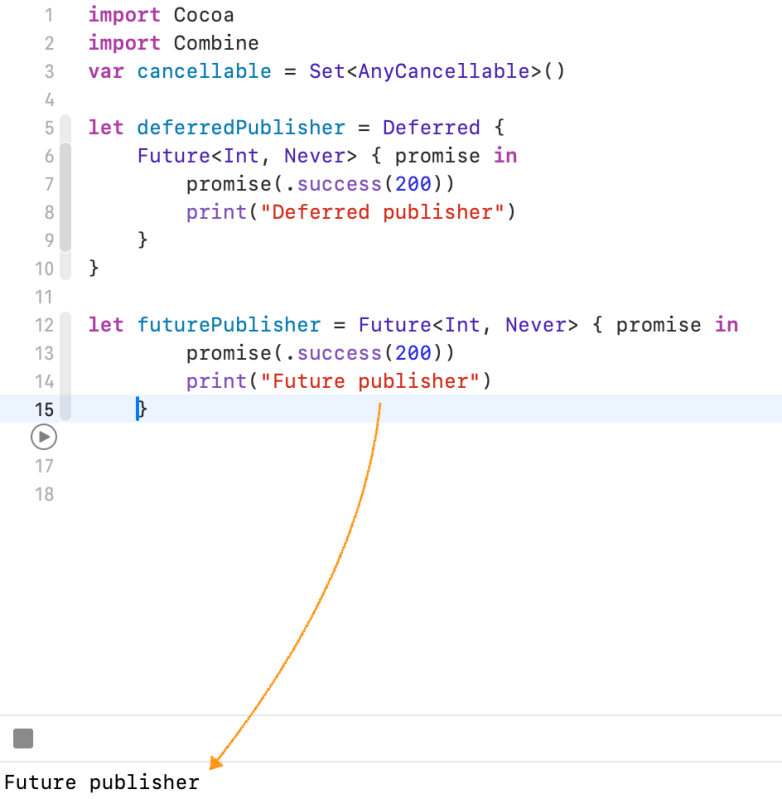
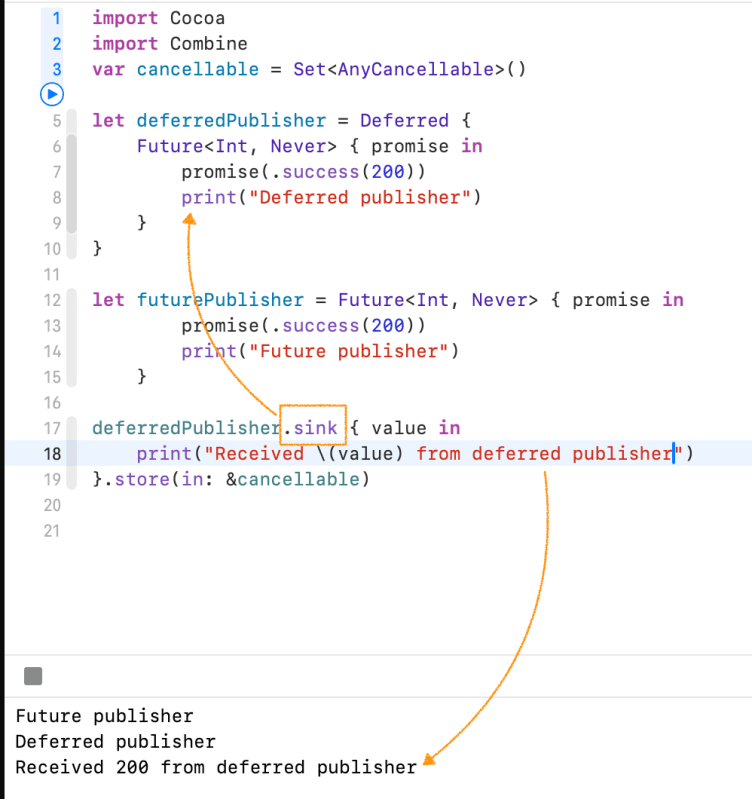
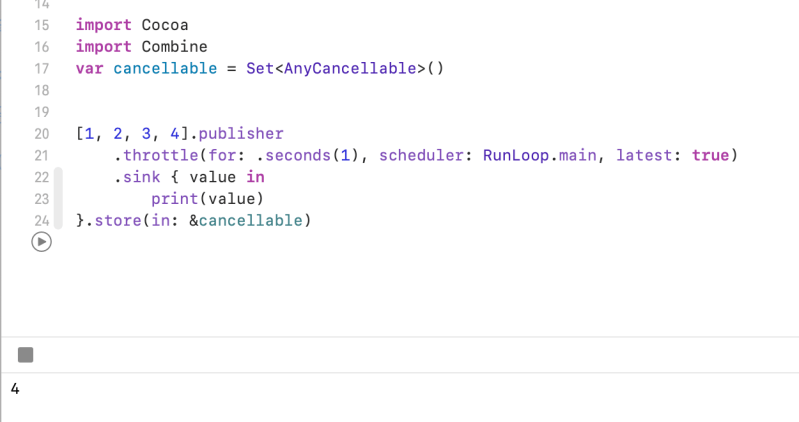
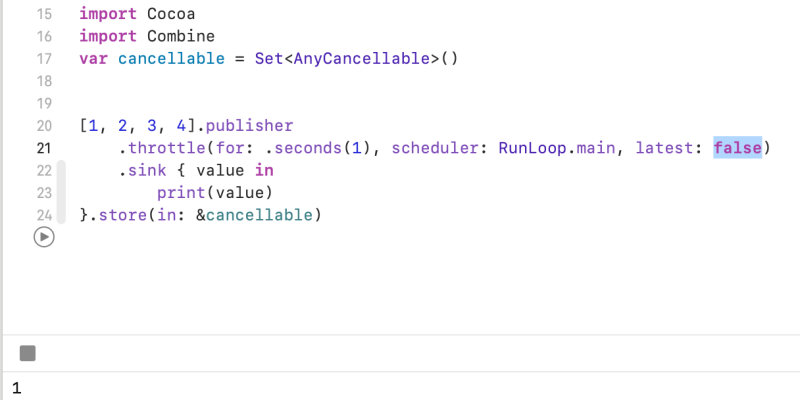
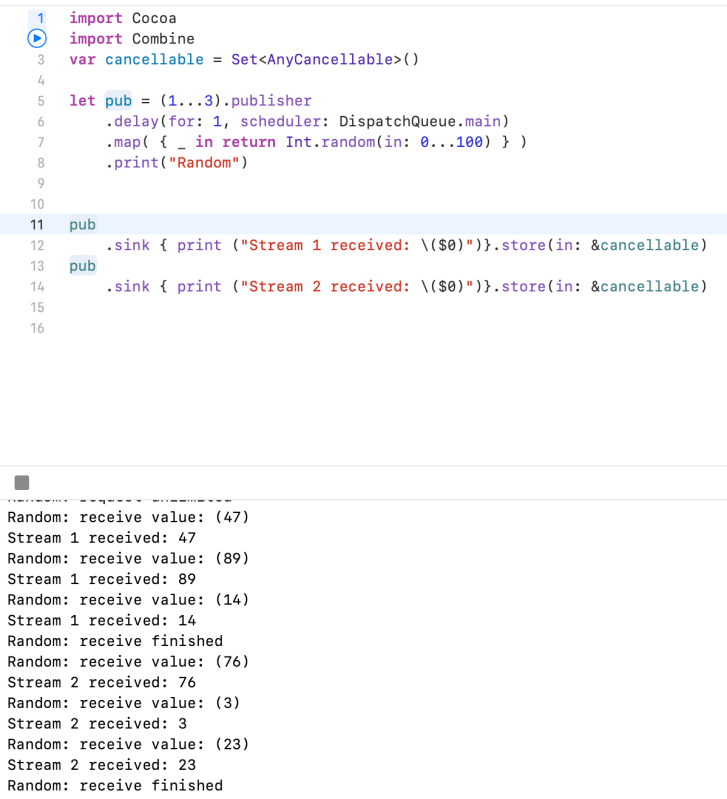
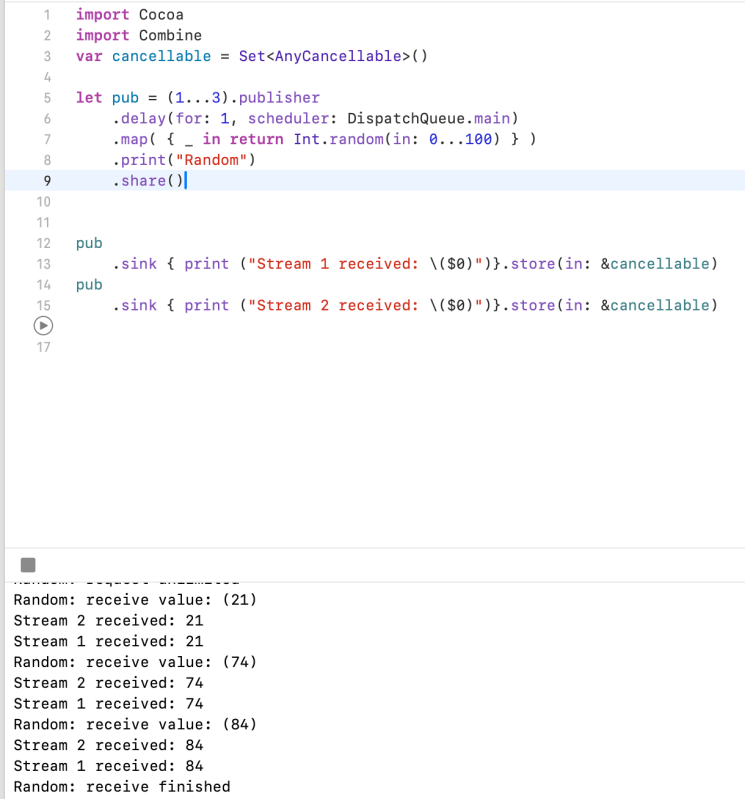
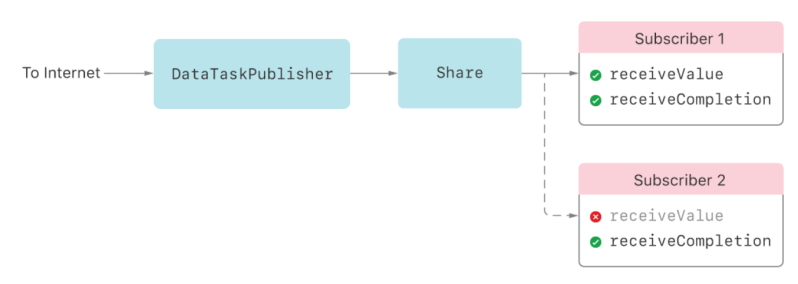
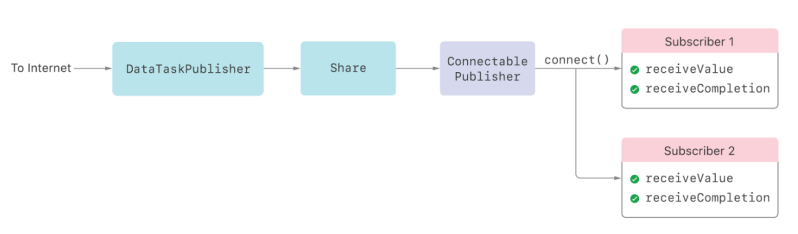



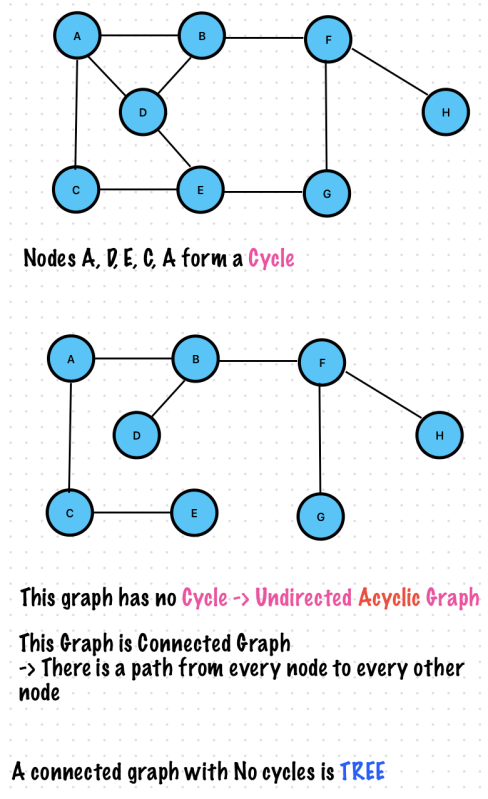

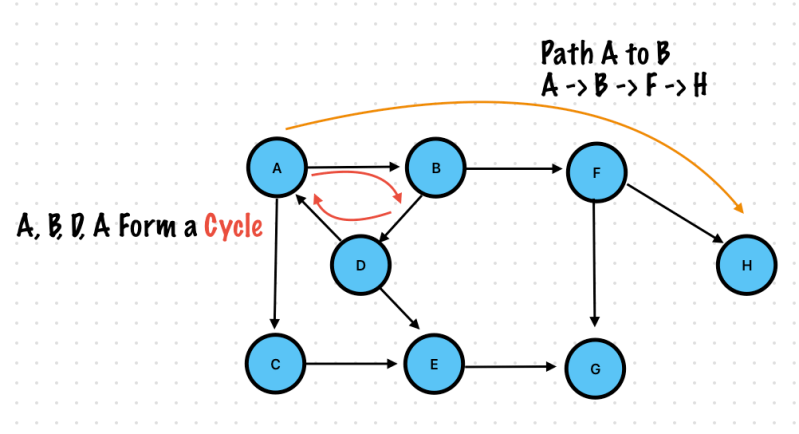
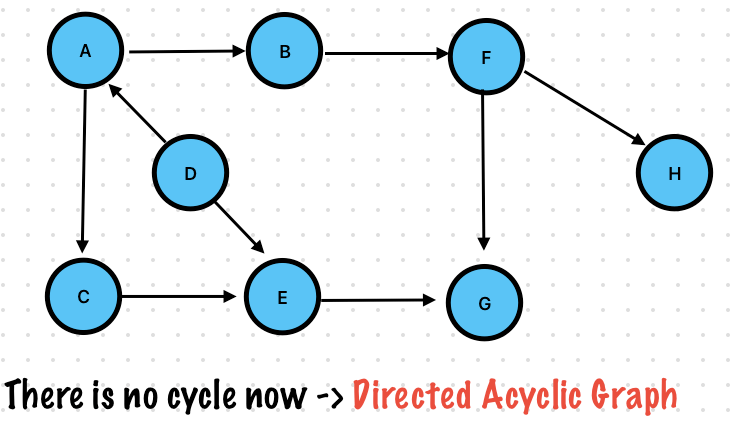

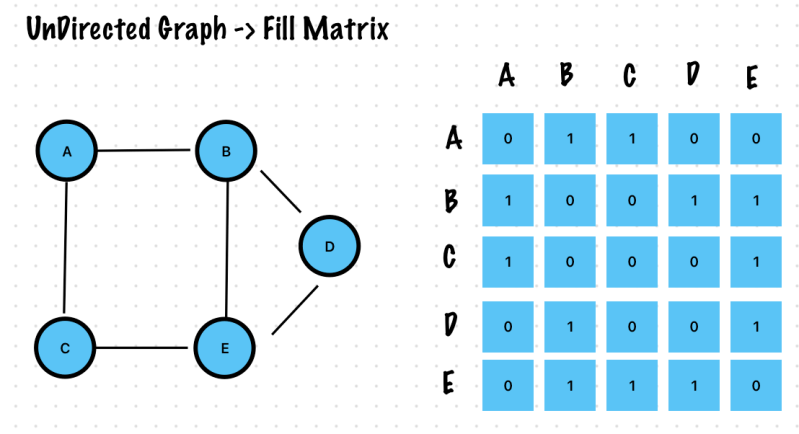
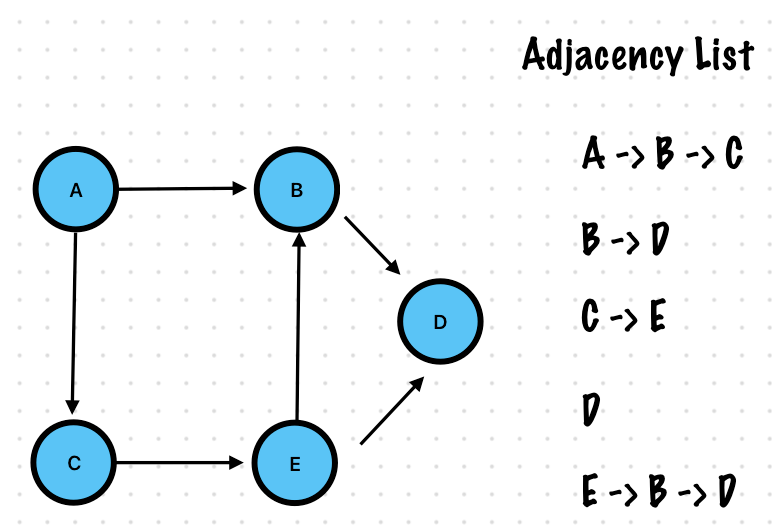
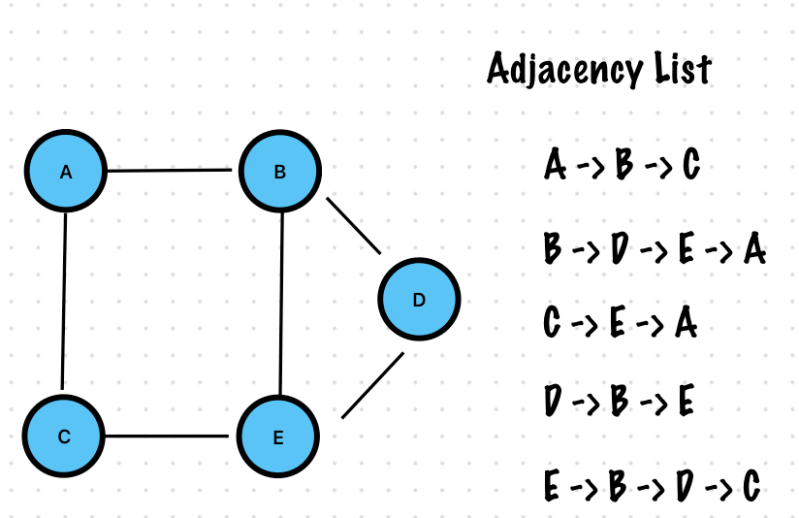
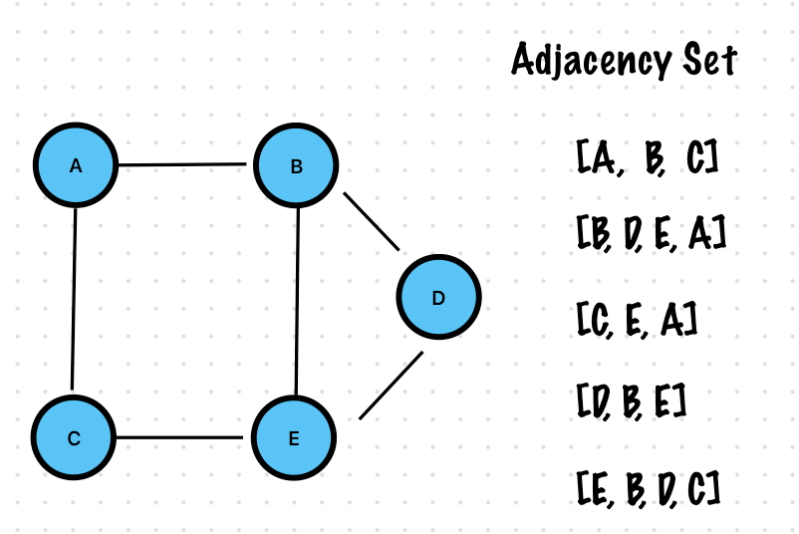
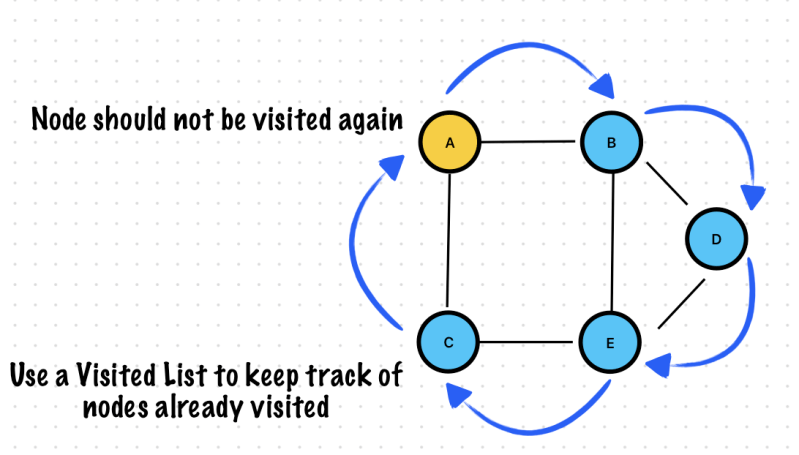
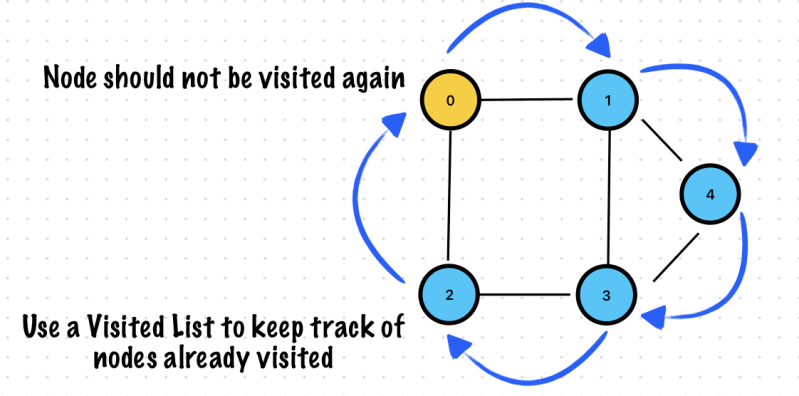

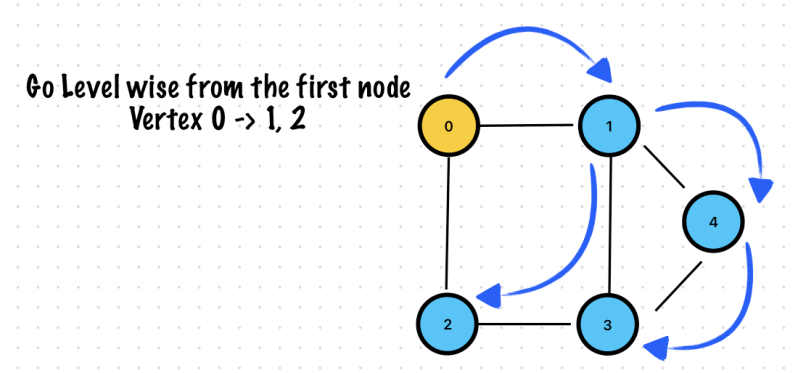
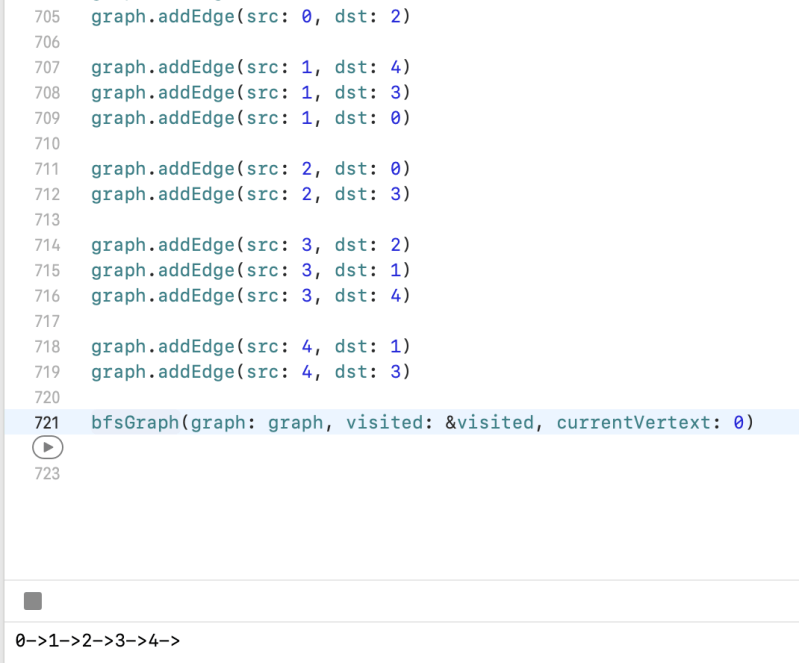


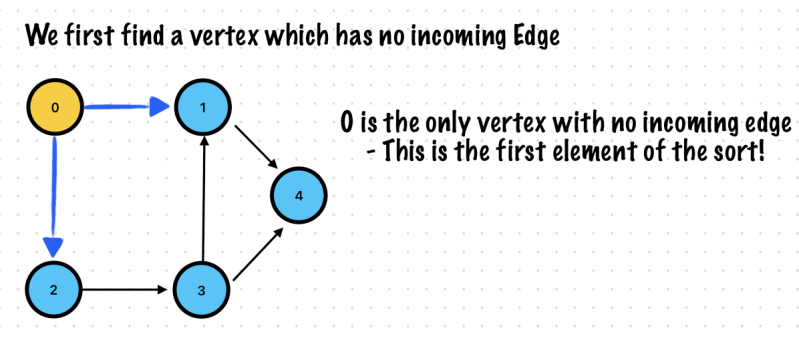
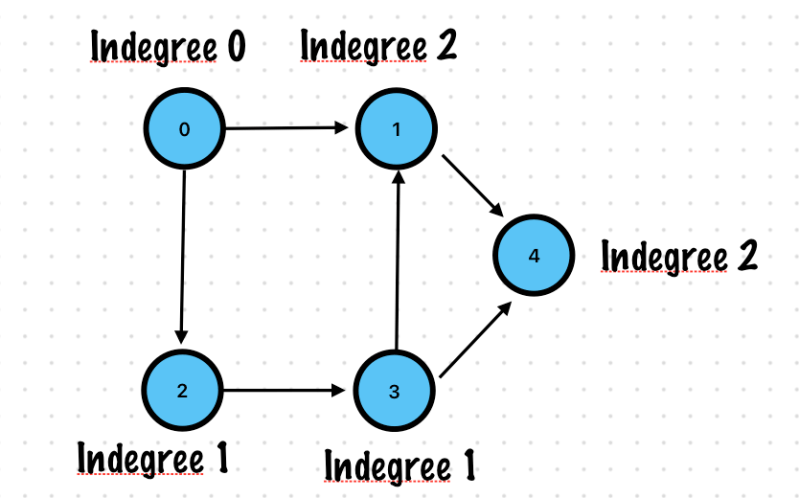

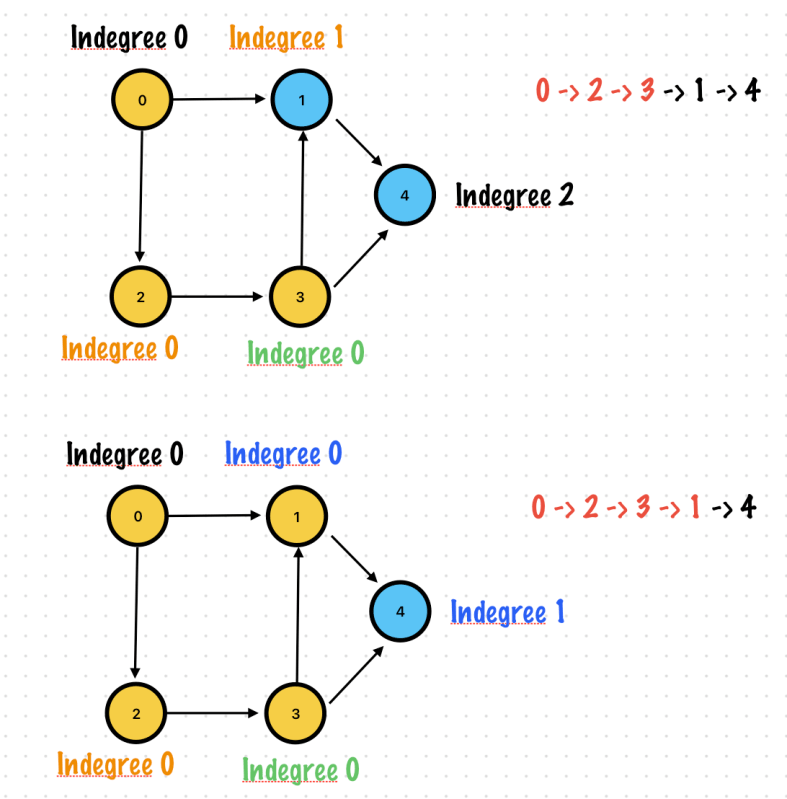

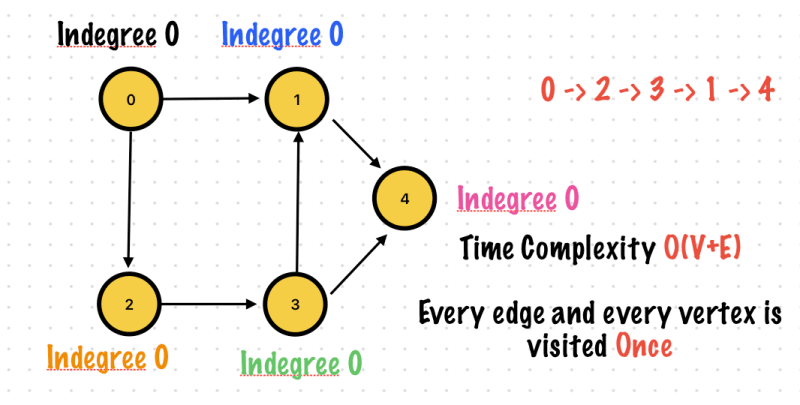



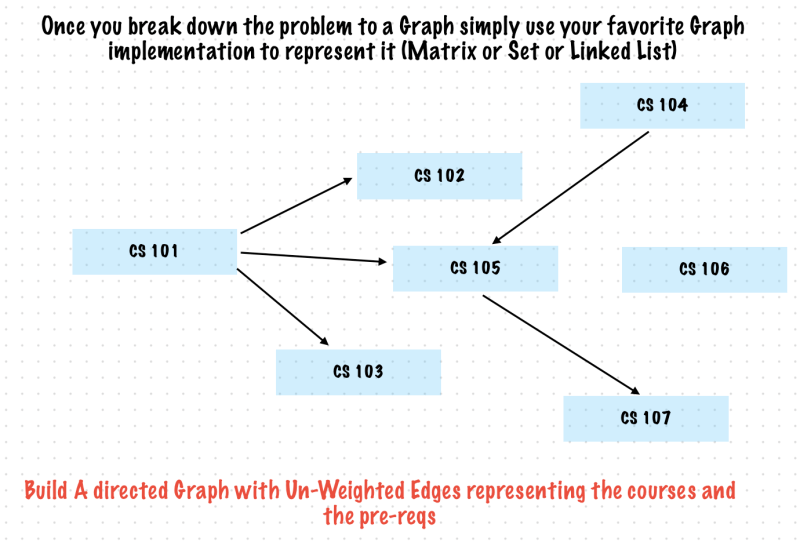
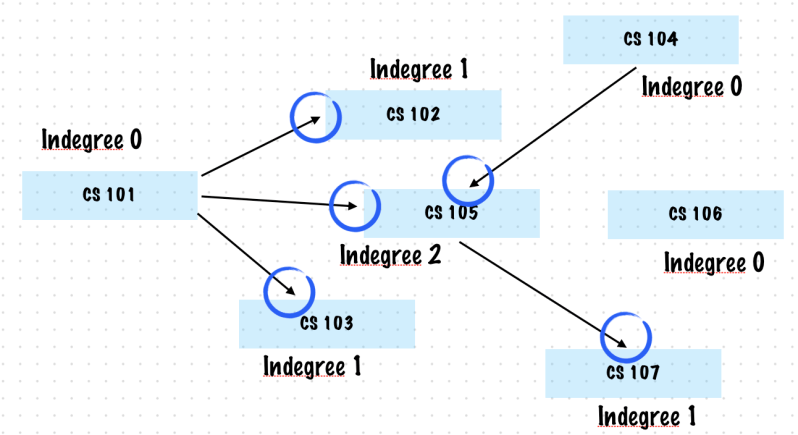
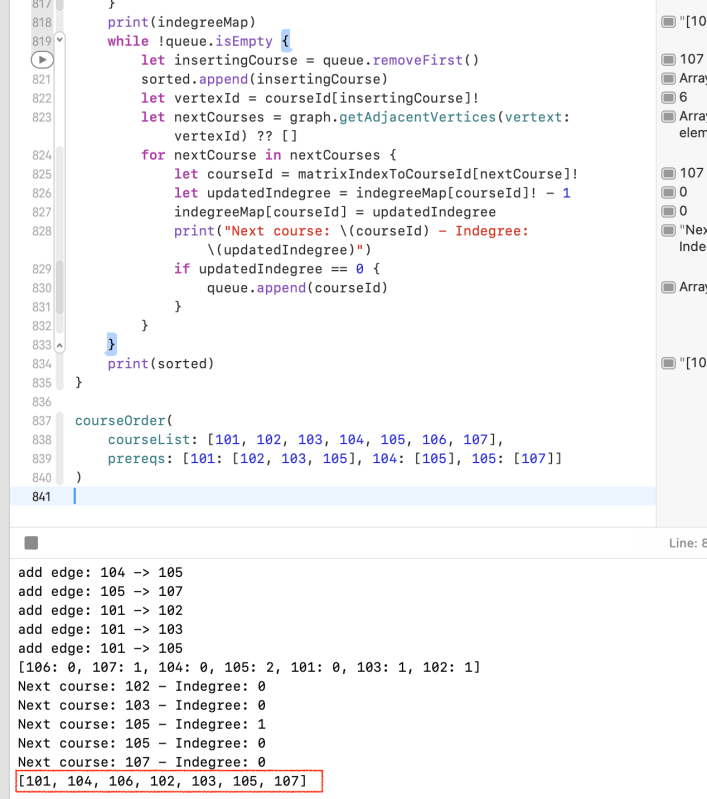

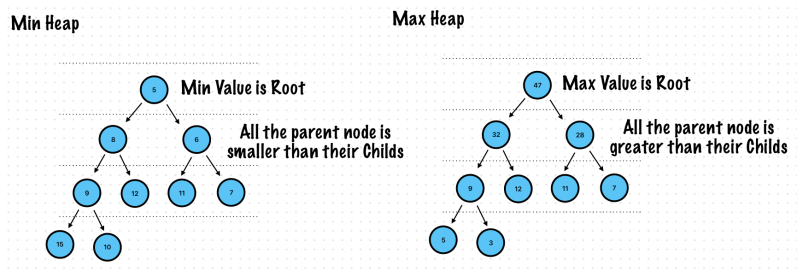
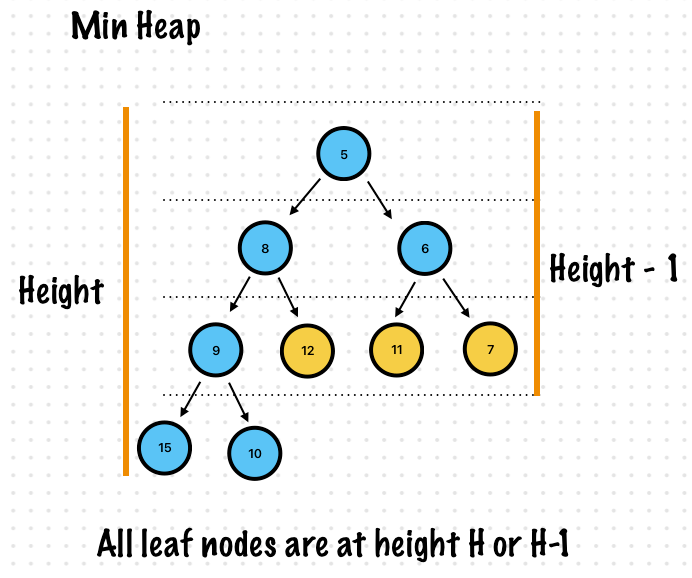


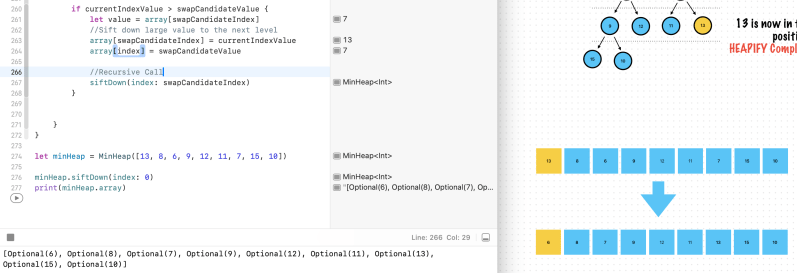

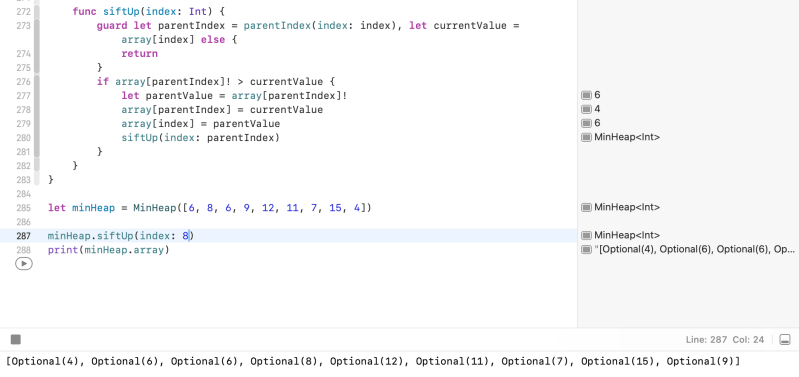
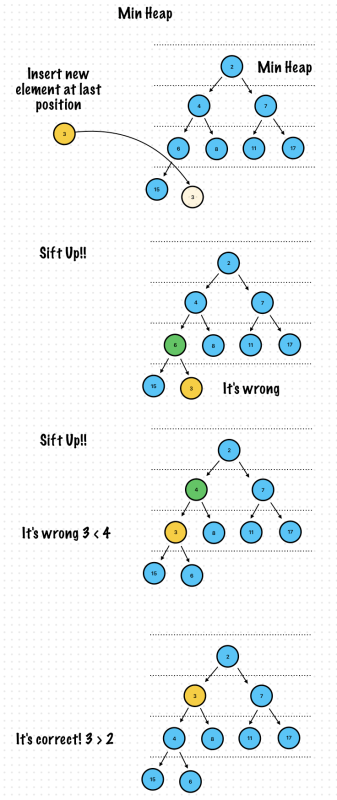
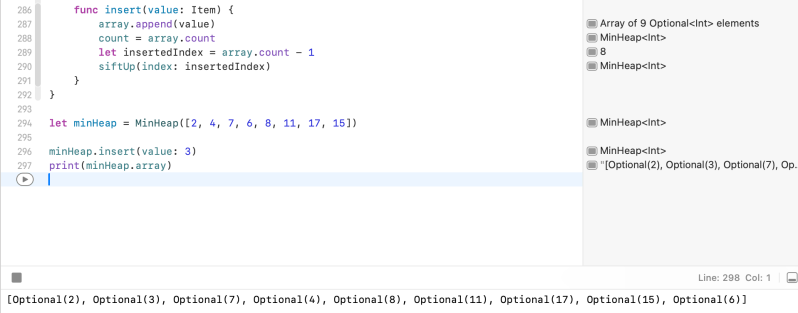
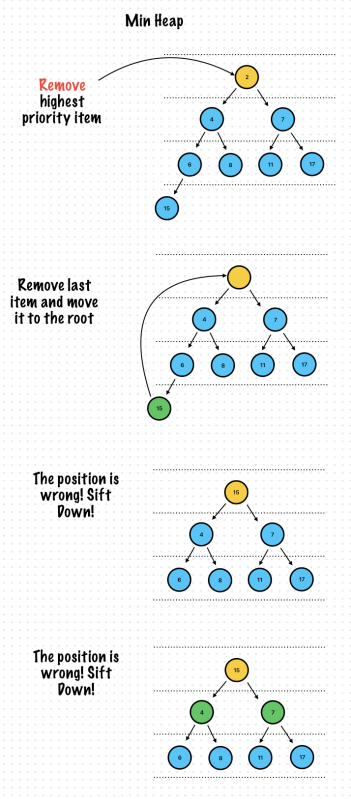



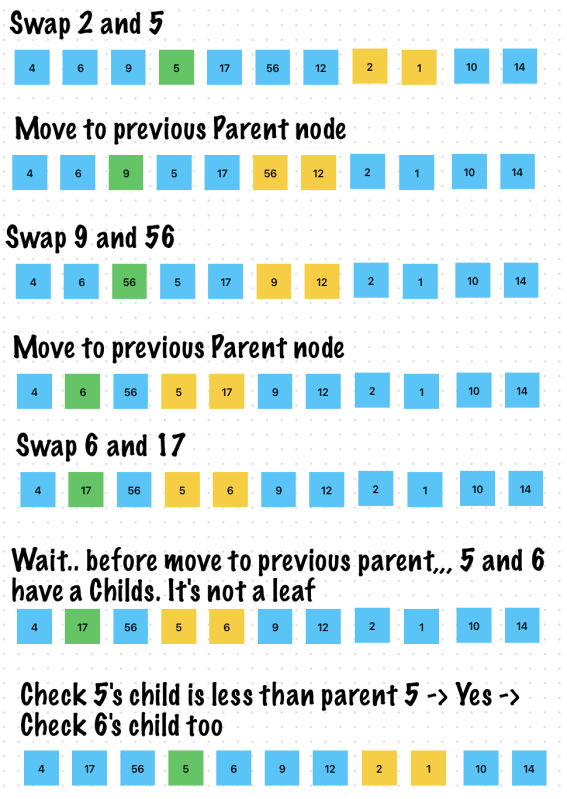
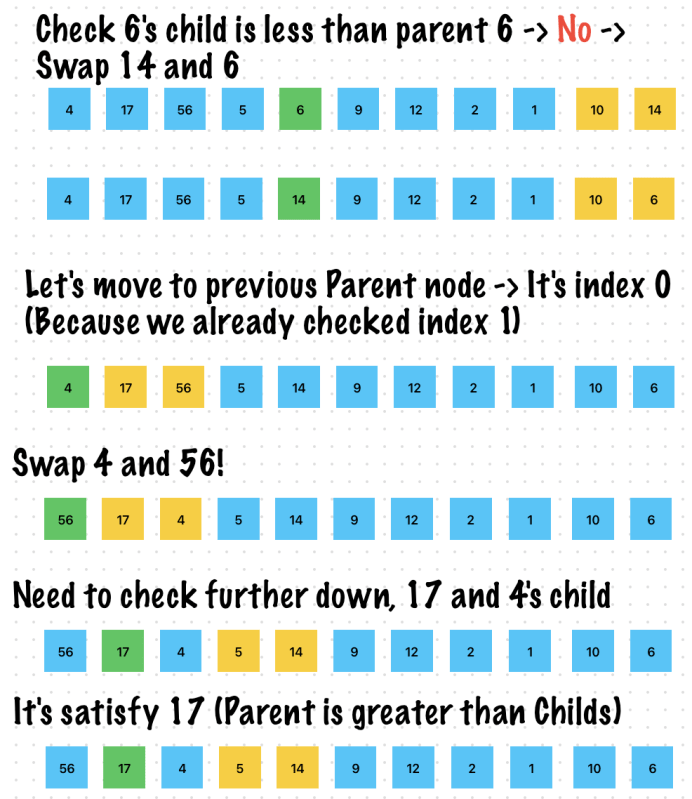


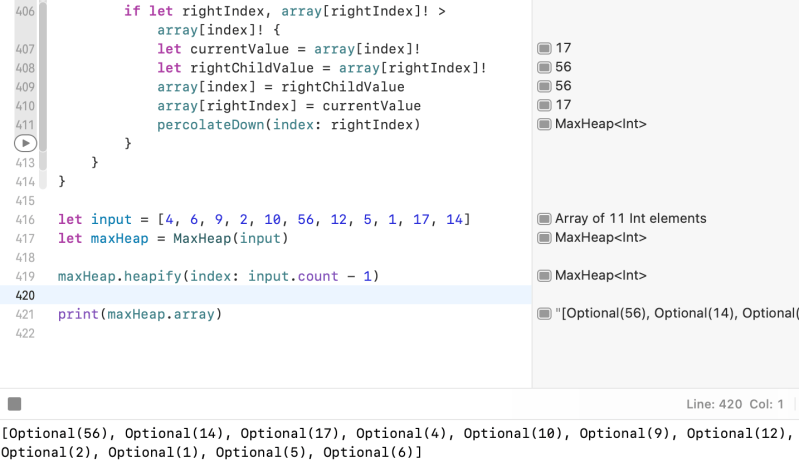

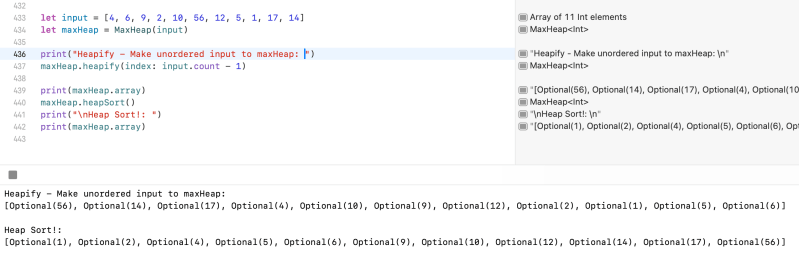

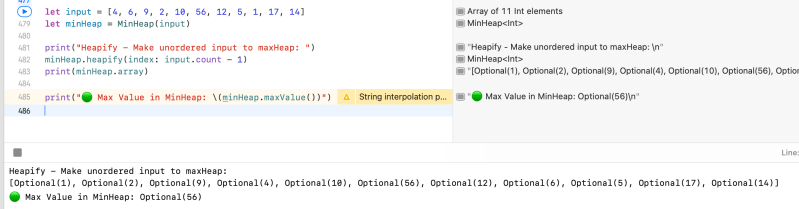





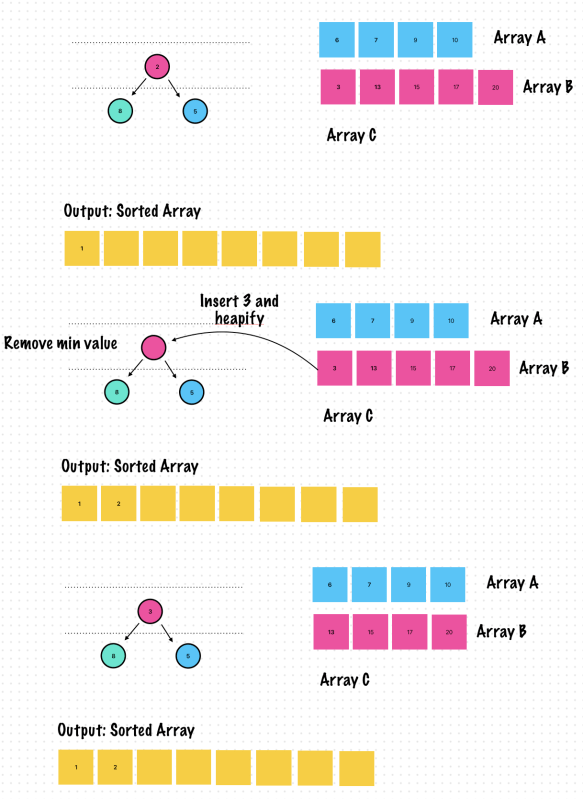



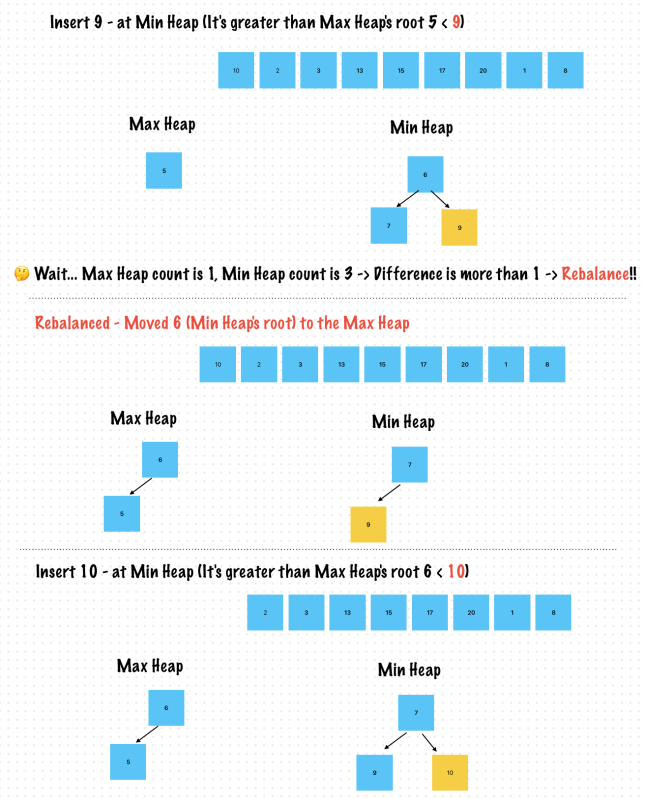
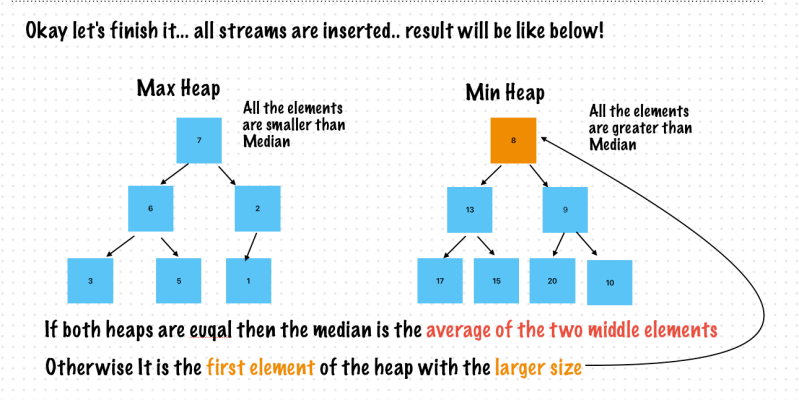


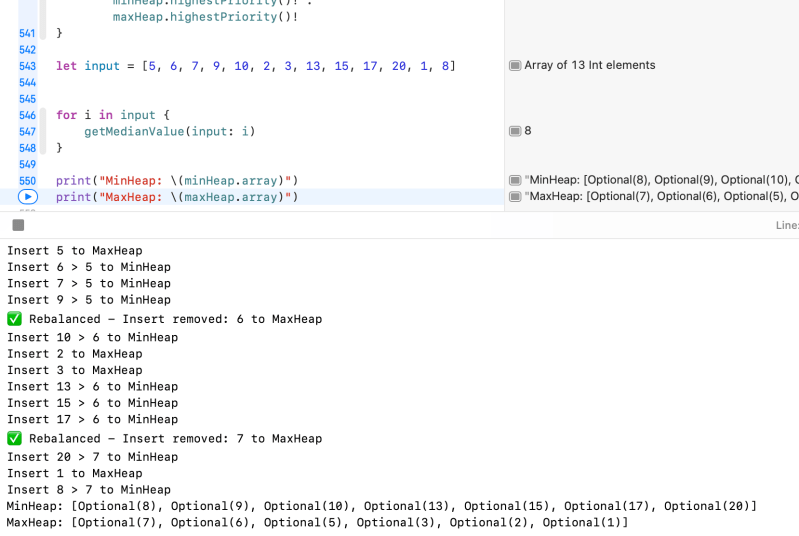

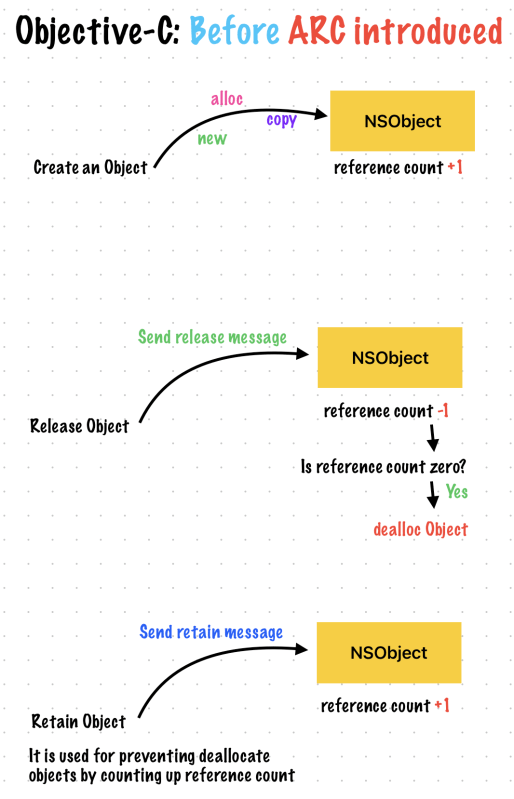



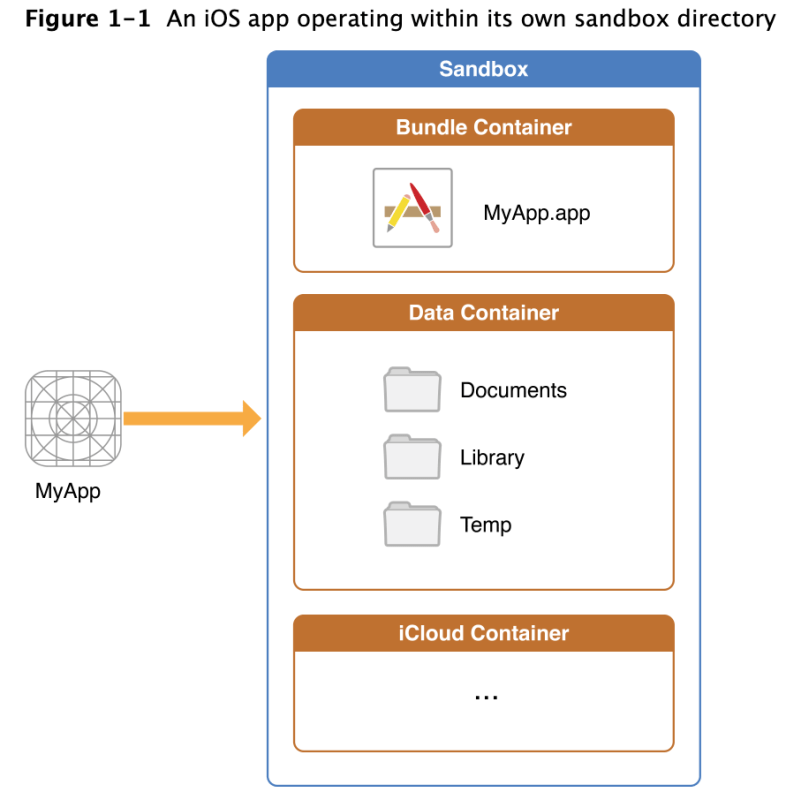
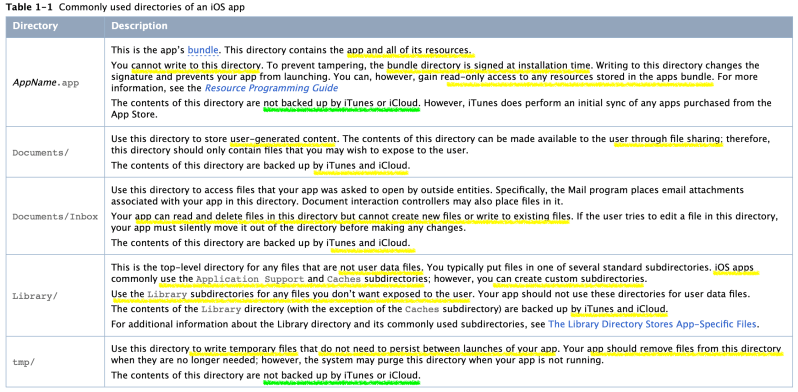


You must be logged in to post a comment.